
eBook - ePub
Probabilistic Data Structures for Blockchain-Based Internet of Things Applications
- 320 pages
- English
- ePUB (mobile friendly)
- Available on iOS & Android
eBook - ePub
Probabilistic Data Structures for Blockchain-Based Internet of Things Applications
About this book
This book covers theory and practical knowledge of Probabilistic data structures (PDS) and Blockchain (BC) concepts. It introduces the applicability of PDS in BC to technology practitioners and explains each PDS through code snippets and illustrative examples. Further, it provides references for the applications of PDS to BC along with implementation codes in python language for various PDS so that the readers can gain confidence using hands on experience. Organized into five sections, the book covers IoT technology, fundamental concepts of BC, PDS and algorithms used to estimate membership query, cardinality, similarity and frequency, usage of PDS in BC based IoT and so forth.
Tools to learn more effectively

Saving Books

Keyword Search

Annotating Text

Listen to it instead
Information
Part III
Probabilistic Data Structures: An Overview
9
Introduction to Probabilistic Data Structures
9.1 Need of Probabilistic Data Structures
There is an exponential increase in the generation of data since last few years. This heavy data growth poses a challenge for industry and academia for storage and query processing. While analyzing logs for huge data sets, it is required to perform different query operations, such as counting unique items, computing frequency of a data item, searching any item in a set, etc. Additionally, we need to probe more complex datasets, such as images, videos, web pages, etc. Clearly, in order to process such query operations on data, it is essential to store data in computer memory. Tapes, hard disk, solid state drives are different types of memory available for a computing system. However, these different types of memory have different characteristics as presented in Fig. 9.1. For example, hard disks are mechanical devices and they are slow to access as compared to main memory integrated on a semiconductor chip which makes querying from database in hard disk time consuming. Hence, for a query, a processor has to every time access the hard disk for the data it requires which clearly would be a slow operation. Also, disk access proves costly as compared to the main memory (that's why a GB of main memory is much costlier than a GB of hard drive).
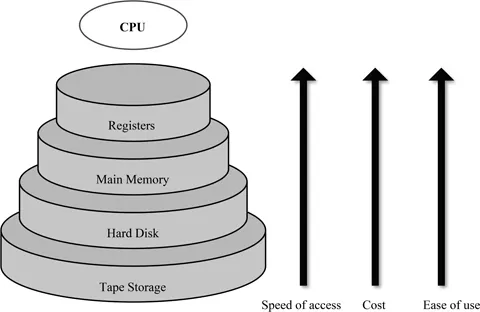
FIGURE 9.1
Computer memory hierarchy.
Computer memory hierarchy.
Besides, a process needs to be in the main memory in order to get executed so, it has to get swapped in from secondary memory to main memory as depicted in Fig. 9.2. Simultaneously, for a developer, main memory is easy to use as creating an array, linked list, or set in main memory is easy as compared to writing files in or out by using a Hadoop database or Apache Solr in secondary storage. These upcoming big data technologies are oftenly used in providing accurate analysis and decision making. These technologies provide distributed data storage and parallel processing. Although the distributed database Hadoop with a heavy processing engine (Spark, MapReduce) is good with batch processing framework where the aim is to improve job throughput rather than handling speed of access issue. Notably, the batch processing of data doesn't impose any time constraints so, it can be stored on disk and queries can be processed in batches. Additionally, the popular approach of using SQL for processing queries on database in secondary storage results in high space complexity. For instance, Powerdrill is a column oriented data storage approach that faces the challenge of high memory and computational overhead for large datasets. However, streaming data requires real-time processing with a minimal delay which is possible with improved speed of access. Moreover, streaming data requires processing in a single pass. So, it is always better to work more in main memory for real-time processing of streaming data along with processing data in a single pass. Subsequently, the growing size of databases and applications dataset demands a compact data structure in order to get managed and handled properly.
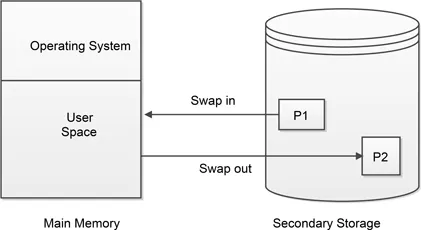
FIGURE 9.2
Memory management via swapping.
Memory management via swapping.
The current scenario of data generation has resulted in the release of new applications that need to deal with a huge volume of data. Conventional algorithms assumption of fitting data in main memory fails when dealing with such a huge amount of data. In this context, streaming algorithms (that process data in one or a few passes while consuming a limited amount of storage and time) are getting popular among researchers.
Unfortunately, in order to fix above mentioned issue, deterministic data structures, such as hash tables, array, binary search tree fail to deal with large data sets as it is difficult to accommodate large streaming data into memory at once. The conventional data structures can't go on the further side of linear processing. Moreover, for large dataset, a polynomial running time complexity served by deterministic data structures is not beneficial. Also, 3 V's (volume, variety, and velocity) of data demands real-time analy...
Table of contents
- Cover
- Half Title
- Title Page
- Copyright Page
- Contents
- Foreword
- Preface
- Biography
- I Background
- II Blockchain Overview
- III Probabilistic Data Structures: An Overview
- IV Integration of Probabilistic Data Structures with Blockchain
- Bibliography
- Index
Frequently asked questions
Yes, you can cancel anytime from the Subscription tab in your account settings on the Perlego website. Your subscription will stay active until the end of your current billing period. Learn how to cancel your subscription
No, books cannot be downloaded as external files, such as PDFs, for use outside of Perlego. However, you can download books within the Perlego app for offline reading on mobile or tablet. Learn how to download books offline
Perlego offers two plans: Essential and Complete
- Essential is ideal for learners and professionals who enjoy exploring a wide range of subjects. Access the Essential Library with 800,000+ trusted titles and best-sellers across business, personal growth, and the humanities. Includes unlimited reading time and Standard Read Aloud voice.
- Complete: Perfect for advanced learners and researchers needing full, unrestricted access. Unlock 1.4M+ books across hundreds of subjects, including academic and specialized titles. The Complete Plan also includes advanced features like Premium Read Aloud and Research Assistant.
We are an online textbook subscription service, where you can get access to an entire online library for less than the price of a single book per month. With over 1 million books across 990+ topics, we’ve got you covered! Learn about our mission
Look out for the read-aloud symbol on your next book to see if you can listen to it. The read-aloud tool reads text aloud for you, highlighting the text as it is being read. You can pause it, speed it up and slow it down. Learn more about Read Aloud
Yes! You can use the Perlego app on both iOS and Android devices to read anytime, anywhere — even offline. Perfect for commutes or when you’re on the go.
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Yes, you can access Probabilistic Data Structures for Blockchain-Based Internet of Things Applications by Neeraj Kumar,Arzoo Miglani in PDF and/or ePUB format, as well as other popular books in Computer Science & Computer Engineering. We have over one million books available in our catalogue for you to explore.