
- 349 pages
- English
- ePUB (mobile friendly)
- Available on iOS & Android
eBook - ePub
About this book
New technologies have enabled us to collect massive amounts of data in many fields. However, our pace of discovering useful information and knowledge from these data falls far behind our pace of collecting the data. Data Mining: Theories, Algorithms, and Examples introduces and explains a comprehensive set of data mining algorithms from various dat
Tools to learn more effectively

Saving Books

Keyword Search

Annotating Text

Listen to it instead
Information
Part I
An Overview of Data Mining
1
Introduction to Data, Data Patterns, and Data Mining
Data mining aims at discovering useful data patterns from massive amounts of data. In this chapter, we give some examples of data sets and use these data sets to illustrate various types of data variables and data patterns that can be discovered from data. Data mining algorithms to discover each type of data patterns are briefly introduced in this chapter. The concepts of training and testing data are also introduced.
1.1 Examples of Small Data Sets
Advanced technologies such as computers and sensors have enabled many activities to be recorded and stored over time, producing massive amounts of data in many fields. In this section, we introduce some examples of small data sets that are used throughout the book to explain data mining concepts and algorithms.
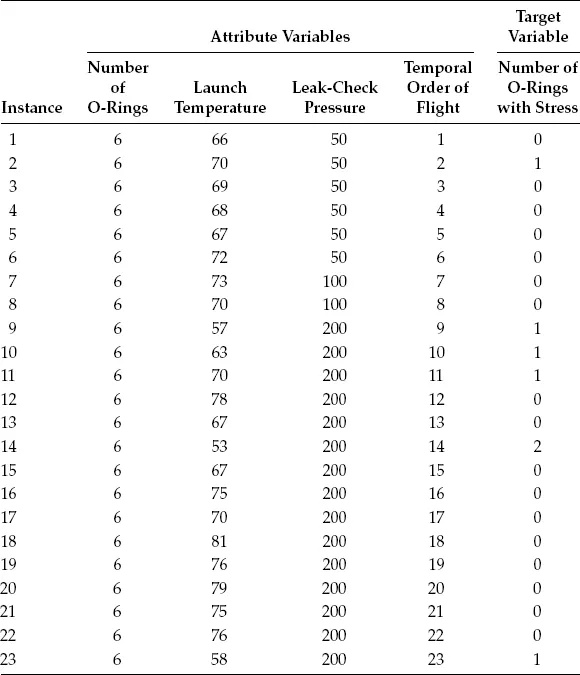
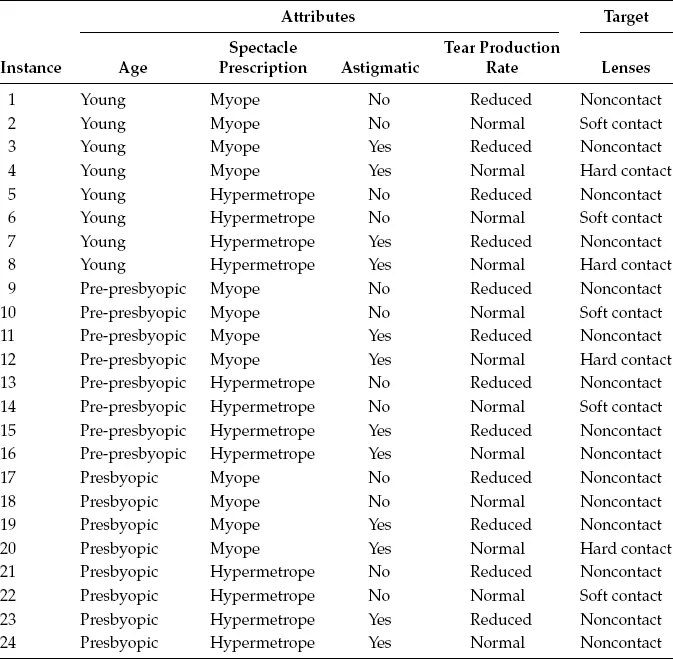
Tables 1.1 through 1.3 give three examples of small data sets from the UCI Machine Learning Repository (Frank and Asuncion, 2010). The balloons data set in Table 1.1 contains data records for 16 instances of balloons. Each balloon has four attributes: Color, Size, Act, and Age. These attributes of the balloon determine whether or not the balloon is inflated. The space shuttle O-ring erosion data set in Table 1.2 contains data records for 23 instances of the Challenger space shuttle flights. There are four attributes for each flight: Number of O-rings, Launch Temperature (°F), Leak-Check Pressure (psi), and Temporal Order of Flight, which can be used to determine Number of O-rings with Stress. The lenses data set in Table 1.3 contains data records for 24 instances for the fit of lenses to a patient. There are four attributes of a patient for each instance: Age, Prescription, Astigmatic, and Tear Production Rate, which can be used to determine the type of lenses to be fitted to a patient.
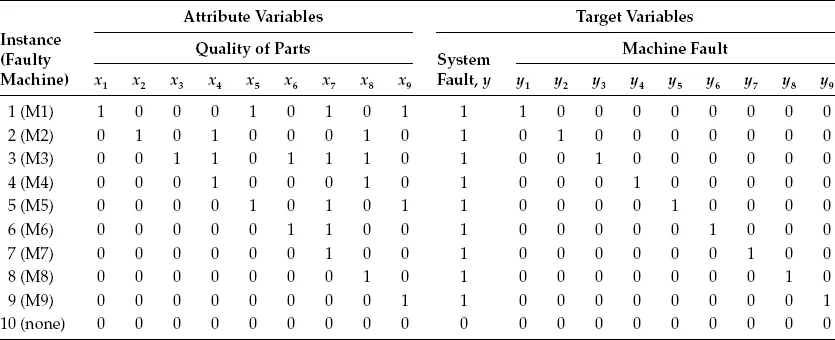
Table 1.4 gives the data set for fault detection and diagnosis of a manufacturing system (Ye et al., 1993). The manufacturing system consists of nine machines, M1, M2, …, M9, which process parts. Figure 1.1 shows the production flows of parts to go through the nine machines. There are some parts that go through M1 first, M5 second, and M9 last, some parts that go through M1 first, M5 second, and M7 last, and so on. There are nine variables, xi, i = 1, 2, …, 9, representing the quality of parts after they go through the nine machines. If parts after machine i pass the quality inspection, xi takes the value of 0; otherwise, xi takes the value of 1. There is a variable, y, representing whether or not the system has a fault. The system has a fault if any of the nine machines is faulty. If the system does not have a fault, y takes the value of 0; otherwise, y takes the value of 1. There are nine variables, yi, i = 1, 2, …, 9, representing whether or not nine machines are faulty, respectively. If machine i does not have a fault, yi takes the value of 0; otherwise, yi takes the value of 1. The fault detection problem is to determine whether or not the system has a fault based on the quality information. The fault detection problem involves the nine quality variables, xi, i = 1, 2, …, 9, and the system fault variable, y. The fault diagnosis problem is to determine which machine has a fault based on the quality information. The fault diagnosis problem involves the nine quality variables, xi, i = 1, 2, …, 9, and the nine variables of machine fault, yi, i = 1, 2, …, 9. There may be one or more machines that have a fault at the same time, or no faulty machine. For example, in instance 1 with M1 being faulty (y1 and y taking the value of 1 and y2, y3, y4, y5, y6, y7, y8, and y9 taking the value of 0), parts after M1, M5, M7, M9 fails the quality inspection with x1, x5, x7, and x9 taking the value of 1 and other quality variables, x2, x3, x4, x6, and x8, taking the value of 0.
TABLE 1.1
Balloon Data Set
Balloon Data Set
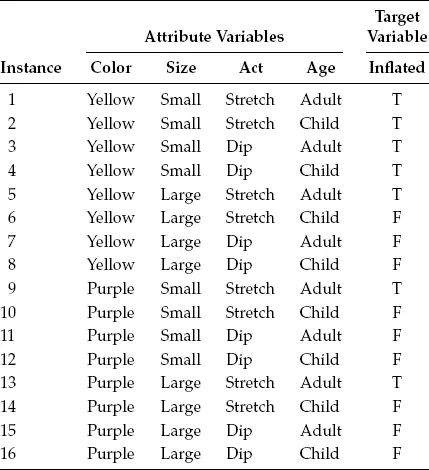
TABLE 1.2
Space Shuttle O-Ring Data Set
Space Shuttle O-Ring Data Set
1.2 Types of Data Variables
The types of data variables affect what data mining algorithms can be applied to a given data set. This section introduces the different types of data variables.
1.2.1 Attribute Variable versus Target Variable
A data set may have attribute variables and target variable(s). The values of the attribute variables are used to determine the values of the target variable(s). Attribute variables and target variables may also be called as independent variables and dependent variables, respectively, to reflect that the values of the target variables depend on the values of the attribute variables. In the balloon data set in Table 1.1, the attribute variables are Color, Size, Act, and Age, and the target variable gives the inflation status of the balloon. In the space shuttle data set in Table 1.2, the attribute variables are Number of O-rings, Launch Temperature, Leak-Check Pressure, and Temporal Order of Flight, and the target variable is the Number of O-rings with Stress.
TABLE 1.3
Lenses Data Set
Lenses Data Set
Some data sets may have only attribute variables. For example, customer purchase transaction data may contain the items purchased by each customer at a store. We have attribute variables representing the items purchased. The interest in the customer purchase transaction data is in finding out what items are often purchased together by customers. Such association patterns of items or attribute variables can be used to design the store layout for sale of items and assist customer shopping. Mining such a data set involves only attribute variables.
TABLE 1.4
Data Set for a Manufacturing System to Detect and Diagnose Faults
Data Set for a Manufacturing System to Detect and Diagnose Faults
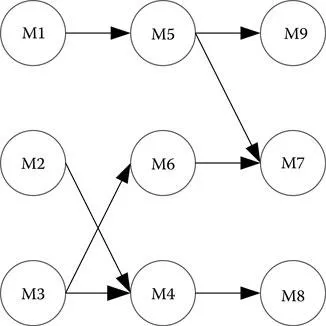
A manufacturing system with nine machines and production flows of parts.
1.2.2 Categorical Variable versus Numeric Variable
A variable can take categorical or numeric values. All the attribute variables and the target variable in the balloon data set take categorical values. For example, two values of the Color attribute, yellow and purple, give two different categories of Color. All the attribute ...
Table of contents
- Cover
- Half Title
- Title Page
- Copyright Page
- Table of Contents
- Preface
- Acknowledgments
- Author
- Part I An Overview of Data Mining
- Part II Algorithms for Mining Classification and Prediction Patterns
- Part III Algorithms for Mining Cluster and Association Patterns
- Part IV Algorithms for Mining Data Reduction Patterns
- Part V Algorithms for Mining Outlier and Anomaly Patterns
- Part VI Algorithms for Mining Sequential and Temporal Patterns
- References
- Index
Frequently asked questions
Yes, you can cancel anytime from the Subscription tab in your account settings on the Perlego website. Your subscription will stay active until the end of your current billing period. Learn how to cancel your subscription
No, books cannot be downloaded as external files, such as PDFs, for use outside of Perlego. However, you can download books within the Perlego app for offline reading on mobile or tablet. Learn how to download books offline
Perlego offers two plans: Essential and Complete
- Essential is ideal for learners and professionals who enjoy exploring a wide range of subjects. Access the Essential Library with 800,000+ trusted titles and best-sellers across business, personal growth, and the humanities. Includes unlimited reading time and Standard Read Aloud voice.
- Complete: Perfect for advanced learners and researchers needing full, unrestricted access. Unlock 1.4M+ books across hundreds of subjects, including academic and specialized titles. The Complete Plan also includes advanced features like Premium Read Aloud and Research Assistant.
We are an online textbook subscription service, where you can get access to an entire online library for less than the price of a single book per month. With over 1 million books across 990+ topics, we’ve got you covered! Learn about our mission
Look out for the read-aloud symbol on your next book to see if you can listen to it. The read-aloud tool reads text aloud for you, highlighting the text as it is being read. You can pause it, speed it up and slow it down. Learn more about Read Aloud
Yes! You can use the Perlego app on both iOS and Android devices to read anytime, anywhere — even offline. Perfect for commutes or when you’re on the go.
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Yes, you can access Data Mining by Nong Ye in PDF and/or ePUB format, as well as other popular books in Economics & Statistics for Business & Economics. We have over one million books available in our catalogue for you to explore.