Recent progress in artificial intelligence (AI) has revolutionized our everyday life. Many AI algorithms have reached human-level performance and AI agents are replacing humans in most professions. It is predicted that this trend will continue and 30% of work activities in 60% of current occupations will be automated.
This success, however, is conditioned on availability of huge annotated datasets to training AI models. Data annotation is a time-consuming and expensive task which still is being performed by human workers. Learning efficiently from less data is a next step for making AI more similar to natural intelligence. Transfer learning has been suggested a remedy to relax the need for data annotation. The core idea in transfer learning is to transfer knowledge across similar tasks and use similarities and previously learned knowledge to learn more efficiently.
In this book, we provide a brief background on transfer learning and then focus on the idea of transferring knowledge through intermediate embedding spaces. The idea is to couple and relate different learning through embedding spaces that encode task-level relations and similarities. We cover various machine learning scenarios and demonstrate that this idea can be used to overcome challenges of zero-shot learning, few-shot learning, domain adaptation, continual learning, lifelong learning, and collaborative learning.
The emergence of data-driven industries, high-performance computing technologies, the Internet of Things (IoT), and crowdsourcing platform has led to the unprecedented deployment of Machine Learning (ML) algorithms and techniques in a broad range of applications. These applications include problems within computer vision, natural language processing, robotics, complex network science, and decision-making, among many others. Despite the diversity of these applications, the common goal for practical purposes is to develop algorithms and techniques that can mimic humans and replace or augment them in tasks at which humans are slow, inefficient, or inaccurate.
Some of the current ML algorithms have reached human-level performance, readily are used in practice, and their impact on the economy can be observed. In the consumer market, we can see that commercial personal assistant robots are available to purchase, the first commercial drone delivery service kicked off recently, autonomous vehicles are being tested at the moment, and even some ML-based medical diagnosis algorithms are as good as trained specialists. Progress in ML and Artificial Intelligence (AI) is not limited to handful of examples. In the stock market, we can see that nine of the ten largest companies by market capital are companies that heavily invest in and use ML [1]. In the labor market, a study predicts that if the current trend continues for another decade, 30 percent of work activities in sixty percent of current occupations will be automated by the year 2030 [138]. It is not easy to judge how accurate this or other similar predictions are, but there are clear signs that demonstrate even the general public is concerned. For example, one key issue in presidential campaigns is addressing the potential socioeconomical consequences of the rapid changes that are going to happen to the labor force as a result of AI and ML advancement [183]. All the above demonstrates that the importance of AI and ML has gone far beyond just a research area and many unexplored aspects need to be addressed by people outside the AI academic community.
Unsurprisingly, research interest in ML has gained huge momentum in academic circles recently as well, partially as the result of commercial successes of ML algorithms. For example, the number of papers that are submitted to main AI conferences has tripled over just the past five years [2] and attendance at the major AI and ML conferences has grown to unprecedented numbers. However, despite their dramatic progress, current ML algorithms still need significant improvement to replace humans in many applications; machine learning is still a fertile ground for academic research. A major deficiency of ML is that current state-of-the-art ML algorithms depend on plentiful and high-quality datasets to train ML models. Generating such datasets has been challenging until quite recently when crowdsourcing platforms such as Amazon Mechanical Turk (AMT) were developed. Since then, data labeling has become a business of its own. Although data labeling has been resolved for common applications, generating high-quality labeled datasets is still time-consuming and potentially infeasible for many more specific applications [192]. Even if a model can be learned using a high-quality labeled training dataset, the data distribution may change over time. Drifts in data distributions will result in distribution discrepancy for the testing data samples, leading to poor model generalization and the need to continually retrain the model. Despite considerable advancement of computing technologies, ML models such as deep neural networks are becoming consistently more complex and more challenging to train. On the other hand, continual model training is not feasible given the current computational power resources. For these reasons, it is important to develop algorithms that can learn selectively to use computational resources efficiently, reuse previously learned knowledge for efficient learning, and avoid redundant learning.
Further improvement seems possible because, in contrast to current ML methods, humans are able to learn much more efficiently. Humans can learn some tasks from only a few examples, generalize their knowledge to conditions that have not been experienced before, and continuously adapt and update their skills to perform a wide range of tasks and problems. This seems possible because humans effectively use knowledge acquired from past experiences and identify similarities across different learning problems. Humans also benefit from collective and collaborative learning by sharing their expertise. Building upon the experiences of other humans eliminates the need to learn everything from scratch. Inspired from these abilities of humans and due to the fact that performance of single-task ML techniques is reaching theoretical learning upper-bounds, research in ML has shifted from learning a single task in isolation to investigating how knowledge can be transferred across different domains, tasks, and agents that are related. A term that has been used to refer to this broad research area is transfer learning. The goal of transfer learning is to improve learning quality and speed of the current ML algorithm through overcoming labeled data scarceness, avoiding redundant learning and model retraining, and using computational power resources efficiently. In particular, since deep neural networks are becoming dominant models in machine learning, training complex models with several millions of parameters has become a standard practice which makes model retraining expensive. Transfer learning can be very useful since labeling millions of data points is not practical for many real-world problems. For these reasons, it has been predicted that “transfer learning will be the next driver of ML success” [158].
In a classic supervised learning setup, the goal is to train a model for a specific task or domain using a labeled training data. Many ML algorithms are implemented by parameterizing a model to form a hypothesis space. The model selection process is implemented by learning parameters through solving an optimization problem over the set of the labeled training dataset. The idea behind this process is that the training dataset represents the data distribution and hence, the optimal model over this set approximates the Bayes-optimal solution. Under quite well-studied conditions, the trained model will generalize well on testing data points that are drawn from the data probability distribution. However, this framework is inapplicable when sufficient labeled data for the learning problem does not exist, i.e., training dataset does not represent the data distribution well, or when the data distribution changes after training the model. As a result, often trained models underperform on new tasks and domains that are not encountered during training. knowledge transfer techniques tackle challenges of labeled data scarceness and distributional drifts through exploiting the knowledge that is gained by learning related tasks or during past experiences.
Various learning scenarios and applications can benefit from knowledge transfer. For example, in many multi-class classification problems in vision domain, there are classes without sufficient labeled data points, potentially none. Learning to transfer knowledge from classes with sufficient labeled data points can help to recognize images that belong to classes with few labeled data points. In some problems within natural language processing, there exists sufficient labeled data in few common-spoken languages, but the labeled data is scarce in many less common-spoken languages. It is desirable to transfer knowledge from more common-spoken languages with sufficient annotated data to learn similar tasks on less common languages. In many robotics applications, e.g., rescue robots, a robot explores the external world and almost certainly encounters situations and conditions that are new and has not been explored before. Transferring knowledge from past experience can help to learn to handle such conditions fast. Even when labeled training data is accessible, knowledge transfer can help to learn more efficiently either in terms of starting from a better initial point, learning speed, or asymptotic performance. We can use many ideas to implement and use knowledge transfer. In this book, we focus on transferring knowledge through embedding spaces that relate several ML problems and capture dependencies and structures across the ML problems. We demonstrate that this common strategy can be used to address the challenges of various learning scenarios. Implementation of some of the algorithms presented in this book are publicly available at https://github.com/mrostami1366.
1.1 Knowledge Transfer through Embedding Space
In a knowledge transfer scenario, the problem that knowledge is gained from is called the source problem, and the problem that knowledge is transferred to is called the target problem. The primary question that needs to be addressed is “how can we transfer knowledge successfully to the target problem(s) given the source problems?”. Many different approaches have been proposed to answer this question. A major goal of AI and ML is to mimic and replicate the abilities of humans. Hence, an approach inspired by the nervous system can be helpful and lead to successful algorithms, e.g., algorithms for blind source separation [45, 188] or reinforcement learning [236]. More specifically, works within Parallel Distributed Processing (PDP) framework suggest that embedding spaces can be used to model cognitive processes as cognition is a result of representing data using synaptic connections that are changed based on experiences [143]. An embedding space can be considered as a way of representing data such that the data representations become meaningful and discriminative for a particular task. Throughout this book, we loosely are inspired from this idea to find relations and correspondences between ML problems by coupling their data representations in a shared embedding space.
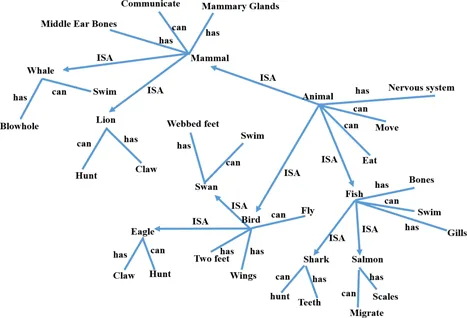
PDP framework has not been the dominant framework for AI. In the early days of AI, modal logic was more a source of inspiration for AI researchers. Following modal logic, early AI models were developed based on using categories and propositions [149]. Quillian suggested that concepts can be organized in hierarchical tree structures similar to tree of life (as denoted in Figure 1.1). In this structure, specific categories are denoted by leaves of more general categories, then propositions that are true about a group of concepts can be stored at the first common ancestor node that all those concepts are leaves of it. Upon forming this structure, we can use it to answer whether a proposition is true about a concept. It only suffices to start from the concept and look into its immediate ancestor node to see if the proposition is stored in that node. If not, we can search the higher level ancestor nodes until the proposition is found, or reaching the root node, which means the proposition is not true.
Figure 1.1 Quillian’s hierarchical model for the broad concept of animals (inspired and adapted from [143]). Each straight line denotes a proposition from the predicate in its start and the subject in its tail with the relation written on it, e.g., “can” and “has”. The arrows denote “IS A” relations and denote one more level of the hierarchy. In addition to direct propositions, hierarchical propositions can be deduced through the ancestor nodes, e.g., “salmon has gill” and salmon “can move”.
Despite intuitiveness of Quillian’s framework, experiments on the human nervous system do not confirm its predictions. For example, this model predicts that it is easier for humans to verify more specific properties of concepts compared to boarder properties. Because these properties are stored closer to the concepts, less search is required. But psychological experiments do not confirm this prediction [156]. Additionally, this idea implies that more specific properties of a concept form a stronger bond with the concept compared to more general properties, but this does not seem to be the case either. Findings related to a special type of neurological disorder, called semantic dementia, provide evidence for an alternative model for cognition. Patients with this disease progressively lose the ability to associate properties with concepts [143]. However, they lose specific properties first, e.g., a zebra has stripes, and gradually lose more general properties, e.g., a zebra has four legs. When the patients lose specific properties of two similar concepts, then he/she cannot distinguish between the two concepts, e.g., a zebra versus a donkey. As a result, patients would draw those concepts similarly which demonstrate that those concepts are encoded similarly in the nervous system. These observations suggest that concepts are grouped according to their properties in the brain in a hierarchical structure. However, concepts that have the same property are grouped such that similar synaptic connections encode all those concepts. As we will see in the next chapters, this process can be modeled mathematically, by assuming that those concepts are mapped in an embedding space that is shared across those concepts. This means that if we represent the human semantic space with a vector space in which each dimension denotes a specific property, e.g., having stripes or being able to swim, then concepts that share many common properties, lie close to each other in this space. An important advantage of this approach is that it is feasible to train models that encode data according to abstract similarities in an embedding space.
Following the above discussion, our goal throughout this book is to represent the data from different ML problems in an embedding space such that the resulting representations would capture relations among several learning domains and tasks. Upon learning this embedding space, we can map data points from different domains and tasks to the shared embedding space and use the relationships in the embedding space to transfer knowledge from (a) source domain(s) to the target domain(s). The common challenge that we need to address in different learning scenarios is how to enforce the embedding space to capture hyper-relations among the ML problems.
1.2 Structure and Organization of the Book
Knowledge transfer problems and challenges can be manifested in a wide range of research areas and learning scenarios. In this book, our contributions are in three major areas of knowledge transfer: cross-domain knowledge transfer, cross-task knowledge transfer, and cross-agent knowledge transfer. Implementation of some of the algorithms presented in this book is publicly available at https://github.com/mrostami1366.
1.2.1 Cross-Domain Knowledge Transfer
Knowledge transfer across related domains is our first focus, e.g., visual and textual domains, which are the two dominant information domains. Cross-domain knowledge transfer is helpful in performing tasks for which obtaining information in a particular domain might be challenging, but easier in a related more accessible domain. Humans always benefit from this type of knowledge transfer. For example, in dark lighting conditions, people usually rely on a combination of haptic perception and imagination to improve their visual perception of an object. This is an example of ...
Table of contents
Cover
Half Title
Title Page
Copyright Page
Dedication
Contents
List of Figures
List of Tables
Preface
Acknowledgment
CHAPTER 1 ▪ Introduction
CHAPTER 2 ▪ Background and Related Work
SECTION I Cross-Domain Knowledge Transfer
CHAPTER 3 ▪ Zero-Shot Image Classification through Coupled Visual and Semantic Embedding Spaces
CHAPTER 4 ▪ Learning a Discriminative Embedding for Unsupervised Domain Adaptation
CHAPTER 5 ▪ Few-Shot Image Classification through Coupled Embedding Spaces
SECTION II Cross-Task Knowledge Transfer
CHAPTER 6 ▪ Lifelong Zero-Shot Learning Using High-Level Task Descriptors
CHAPTER 7 ▪ Complementary Learning Systems Theory for Tackling Catastrophic Forgetting
CHAPTER 8 ▪ Continual Concept Learning
SECTION III Cross-Agent Knowledge Transfer
CHAPTER 9 ▪ Collective Lifelong Learning for Multi-Agent Networks
CHAPTER 10 ▪ Concluding Remarks and Potential Future Research Directions
Bibliography
Index
Frequently asked questions
Yes, you can cancel anytime from the Subscription tab in your account settings on the Perlego website. Your subscription will stay active until the end of your current billing period. Learn how to cancel your subscription
No, books cannot be downloaded as external files, such as PDFs, for use outside of Perlego. However, you can download books within the Perlego app for offline reading on mobile or tablet. Learn how to download books offline
Perlego offers two plans: Essential and Complete
Essential is ideal for learners and professionals who enjoy exploring a wide range of subjects. Access the Essential Library with 800,000+ trusted titles and best-sellers across business, personal growth, and the humanities. Includes unlimited reading time and Standard Read Aloud voice.
Complete: Perfect for advanced learners and researchers needing full, unrestricted access. Unlock 1.4M+ books across hundreds of subjects, including academic and specialized titles. The Complete Plan also includes advanced features like Premium Read Aloud and Research Assistant.
Both plans are available with monthly, semester, or annual billing cycles.
We are an online textbook subscription service, where you can get access to an entire online library for less than the price of a single book per month. With over 1 million books across 990+ topics, we’ve got you covered! Learn about our mission
Look out for the read-aloud symbol on your next book to see if you can listen to it. The read-aloud tool reads text aloud for you, highlighting the text as it is being read. You can pause it, speed it up and slow it down. Learn more about Read Aloud
Yes! You can use the Perlego app on both iOS and Android devices to read anytime, anywhere — even offline. Perfect for commutes or when you’re on the go. Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Yes, you can access Transfer Learning through Embedding Spaces by Mohammad Rostami in PDF and/or ePUB format, as well as other popular books in Computer Science & Artificial Intelligence (AI) & Semantics. We have over one million books available in our catalogue for you to explore.