
- 288 pages
- English
- ePUB (mobile friendly)
- Available on iOS & Android
eBook - ePub
Artificial Intelligence and Deep Learning in Pathology
About this book
Recent advances in computational algorithms, along with the advent of whole slide imaging as a platform for embedding artificial intelligence (AI), are transforming pattern recognition and image interpretation for diagnosis and prognosis. Yet most pathologists have just a passing knowledge of data mining, machine learning, and AI, and little exposure to the vast potential of these powerful new tools for medicine in general and pathology in particular. In Artificial Intelligence and Deep Learning in Pathology, Dr. Stanley Cohen covers the nuts and bolts of all aspects of machine learning, up to and including AI, bringing familiarity and understanding to pathologists at all levels of experience.- Focuses heavily on applications in medicine, especially pathology, making unfamiliar material accessible and avoiding complex mathematics whenever possible.- Covers digital pathology as a platform for primary diagnosis and augmentation via deep learning, whole slide imaging for 2D and 3D analysis, and general principles of image analysis and deep learning.- Discusses and explains recent accomplishments such as algorithms used to diagnose skin cancer from photographs, AI-based platforms developed to identify lesions of the retina, using computer vision to interpret electrocardiograms, identifying mitoses in cancer using learning algorithms vs. signal processing algorithms, and many more.
Tools to learn more effectively

Saving Books

Keyword Search

Annotating Text

Listen to it instead
Information
Chapter 1
The evolution of machine learning: past, present, and future
Stanley Cohen, MD 1 , 2 , 3 1 Emeritus Chair of Pathology & Emeritus Founding Director Center for Biophysical Pathology Rutgers-New Jersey Medical School, Newark, NJ, United States 2 Adjunct Professor of Pathology Perelman Medical School University of Pennsylvania, Philadelphia, PA, United States 3 Adjunct Professor of Pathology Kimmel School of Medicine Jefferson University, Philadelphia, PA, United States
Abstract
The earliest computers were designed to perform complex calculations, and their architecture allowed for the storage of not only data but also the instructions as to how to manipulate that data. This evolved to the point where the computer processed data according to a structure model of the real world, expressible in mathematical terms. The computer did not learn but was merely following instructions. The next step was to create a set of instructions that would allow the computer to learn from experience, i.e., to extract its own rules from large amounts of data and use those rules for classification and prediction. This was the beginning of machine learning and has led to the field that is collectively defined as artificial intelligence (AI). A major breakthrough came with the implementation of algorithms that were loosely modeled on brain architecture, with multiple interconnecting units sharing weighted puts among them, organized in computational layers (deep learning). AI has already revolutionized many aspects of modern life and is finding application in biomedical research and clinical practice at an accelerating rate.
Keywords
Capsule; Core memory; Graphical; Instruction set; Neural networks; Neuromorphic computing; Probability; Statistics support vectors
Introduction
The first computers were designed solely to perform complex calculations rapidly. Although conceived in the 1800s, and theoretical underpinnings developed in the early 1900s, it was not until ENIAC was built that the first practical computer can be said to have come into existence. The acronym ENIAC stands for Electronic Numerical Integrator and Calculator. It occupied a 20 × 40 foot room, and contained over 18,000 vacuum tubes. From that time until the mid-20th century, the programs that ran on the descendants of ENIAC were rule based, in that the machine was given a set of instructions to manipulate data based upon mathematical, logical, and/or probabilistic formulas. The difference between an electronic calculator and a computer is that the computer encodes not only numeric data but also the rules for the manipulation of these data (encoded as number sequences).
There are three basic parts to a computer: core memory, where programs and data are stored, a central processing unit that executes the instructions and returns the output of that computation to memory for further use, and devices for input and output of data. High-level programming languages take as input program statements and translate them into the (numeric) information that a computer can understand. Additionally, there are three basic concepts that are intrinsic to every programming language: assignment, conditionals, and loops. In a computer, x = 5 is not a statement about equality. Instead, it means that the value 5 is assigned to x. In this context, X = X + 2 though mathematically impossible makes perfect sense. We add 2 to whatever is in X (in this case, 5) and the new value (7) now replaces that old value (5) in X. It helps to think of the = sign as meaning that the quantity on the left is replaced by the quantity on the right. A conditional is easier to understand. We ask the computer to make a test that has two possible results. If one result holds, then the computer will do something. If not, it will do something else. This is typically an IF-THEN statement. IF you are wearing a green suit with yellow polka dots, PRINT “You have terrible taste!“ IF NOT print “There is still hope for your sartorial sensibilities.” Finally, a LOOP enables the computer to perform a single instruction or set of instructions a given number of times. From these simple building blocks, we can create instructions to do extremely complex computational tasks on any input.
The traditional approach to computing involves encoding a model of the problem based on a mathematical structure, logical inference, and/or known relationships within the data structure. In a sense, the computer is testing your hypothesis with a limited set of data but is not using that data to inform or modify the algorithm itself. Correct results provide a test of that computer model, and it can then be used to work on larger sets of more complex data. This rules-based approach is analogous to hypothesis testing in science. In contrast, machine learning is analogous to hypothesis-generating science. In essence, the machine is given a large amount of data and then models its internal state so that it becomes increasingly accurate in its predictions about the data. The computer is creating its own set of rules from data, rather than being given ad hoc rules by the programmer. In brief, machine learning uses standard computer architecture to construct a set of instructions that, instead of doing direct computation on some inputted data according to a set of rules, uses a large number of known examples to deduce the desired output when an unknown input is presented. That kind of high-level set of instructions is used to create the various kinds of machine learning algorithms that are in general use today. Most machine learning programs are written in PYTHON programming language, which is both powerful and one of the easiest computer languages to learn. A good introduction and tutorial that utilizes biological examples is Ref. [1].
Rules-based versus machine learning: a deeper look
Consider the problem of distinguishing squares and rectangles and circles from each other. One way to approach this problem using a rules-based program would be to calculate relationships between area and circumference for each shape by using geometric-based formulas, and then comparing the measurements of a novel unknown sample to those values for the best fit, which will define its shape. One could also simply count edges, defining a circle as having zero edges, and use that information to correctly classify the unknown.
The only hitch here would be the necessity to know pi for the case of the circle. But that is also easy to obtain. Archimedes did this somewhere about 250 BCE by using geometric formula to calculate the areas of two regular polygons; one polygon inscribed inside the circle and the other the polygon with which the circle was circumscribed (Fig. 1.1).
Since the actual area of the circle lies between the areas of the inscribed and circumscribed polygons, the calculable areas of these polygons set upper and layer bounds for the area of the circle. Without a computer, Archimedes showed that pi is between 3.1408 and 3.1428. Using computers, we can now do this calculation for polygons with very large numbers of sides and reach an approximate value of pi to how many decimal places we require. For a more “modern” approach, we can use a computer to sum a very large number of terms of an infinite series that converges to pi. There are many such series, the first of which having been described in the 14th century.

Wikipedia commons; Public domain.
These rules-based programs are also capable of simulations; as an example, pi can be computed by simulation. For example, if we have a circle quadrant of radius = 1 embedded in a square target board with sides = 1 units, and throw darts at the board so that they randomly land somewhere within the board, the probability of a hit within the circle segment is the ratio of the area of that segment to the area of the whole square, which by simple geometry is pi/4. We can simulate this experiment by computer, by having it pick pairs of random numbers (each between zero and one) and using these as X-Y coordinates to compute the location of a simulated hit. The computer can keep track of both the ratio of the number of hits landing within the circle quadrant and the total number of hits anywhere on the board, and this ratio is then equal to pi/4. This is illustrated in Fig. 1.2.
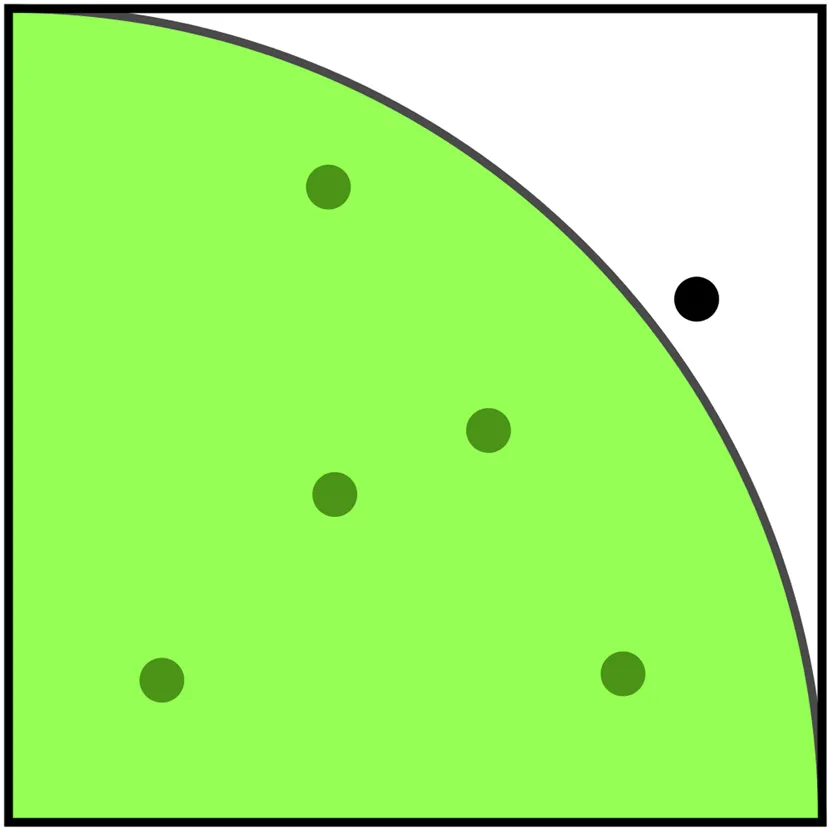
From Wikipedia commons; public domain.
In the example shown in Fig. 1.2, the value of pi is approximately 3.3, based on only 6 tosses. With only a few more tosses we can beat Archimedes, and with a very large number of tosses we can come close to the best value of pi obtained by other means. Because this involves random processes, it is known as Monte Carlo simulation.
Machine learning is quite different. Consider a program that is created to distinguish between squares and circles. For machine learning, all we have to do is present a large number of known squares and circles, each labeled with its correct identity. From this labeled data the computer creates its own set of rules, which are not given to it by the programmer. The machine uses its accumulated experience to ultimately correctly classify an unknown image. There is no need for the programmer to explicitly define the parameters that make the shape into a circle or square. There are many different kinds of machine learning strategies that can do this.
In the most sophisticated forms of machine learning such as neural networks (deep learning), the internal representations by which the computer arrives at a classification are not directly observable or understandable by the programmer. As the program gets more and more labeled samples, it gets better and better at distinguishing the “roundness,” or “squareness” of new data that it has never seen before. It is using prior experience to improve its discriminative ability, and the data itself need not be tightly constrained. In this example, the program can arrive at a decision that is independent of the size, color, and even regularity of the shape. We call this artificial intelligence (AI), since it seems more analogous to the way human beings behave than traditional computing.
Varieties of machine learning
The age of machine learning essentially began with the work of pioneers such as Marvin Minsky and Frank Rosenblatt who described the earliest neural networks. However, this approach languished for a number of reasons including the lack of algorithms that could generalize to most real-world problems, the primitive nature of input storage, and computation in that period. The major conceptual innovations that moved the field forward were backpropagation and convolution, which we will discuss in detail in a later chapter. Meanwhile, other learning algorithms that were being developed also went beyond simply rule-based calculation and involved inferences from large amounts of data. These all address the problem of classifying an unknown instance based upon the previous training of the algorithm with a known dataset.
Most, but not all, algorithms fall into three categories. Classification can be based on clustering of data points in an abstract multidimensional space (support vect...
Table of contents
- Cover image
- Title page
- Table of Contents
- Copyright
- Dedication
- Contributors
- Preface
- Chapter 1. The evolution of machine learning: past, present, and future
- Chapter 2. The basics of machine learning: strategies and techniques
- Chapter 3. Overview of advanced neural network architectures
- Chapter 4. Complexity in the use of artificial intelligence in anatomic pathology
- Chapter 5. Dealing with data: strategies of preprocessing data
- Chapter 6. Digital pathology as a platform for primary diagnosis and augmentation via deep learning
- Chapter 7. Applications of artificial intelligence for image enhancement in pathology
- Chapter 8. Precision medicine in digital pathology via image analysis and machine learning
- Chapter 9. Artificial intelligence methods for predictive image-based grading of human cancers
- Chapter 10. Artificial intelligence and the interplay between tumor and immunity
- Chapter 11. Overview of the role of artificial intelligence in pathology: the computer as a pathology digital assistant
- Index
Frequently asked questions
Yes, you can cancel anytime from the Subscription tab in your account settings on the Perlego website. Your subscription will stay active until the end of your current billing period. Learn how to cancel your subscription
No, books cannot be downloaded as external files, such as PDFs, for use outside of Perlego. However, you can download books within the Perlego app for offline reading on mobile or tablet. Learn how to download books offline
Perlego offers two plans: Essential and Complete
- Essential is ideal for learners and professionals who enjoy exploring a wide range of subjects. Access the Essential Library with 800,000+ trusted titles and best-sellers across business, personal growth, and the humanities. Includes unlimited reading time and Standard Read Aloud voice.
- Complete: Perfect for advanced learners and researchers needing full, unrestricted access. Unlock 1.4M+ books across hundreds of subjects, including academic and specialized titles. The Complete Plan also includes advanced features like Premium Read Aloud and Research Assistant.
We are an online textbook subscription service, where you can get access to an entire online library for less than the price of a single book per month. With over 1 million books across 990+ topics, we’ve got you covered! Learn about our mission
Look out for the read-aloud symbol on your next book to see if you can listen to it. The read-aloud tool reads text aloud for you, highlighting the text as it is being read. You can pause it, speed it up and slow it down. Learn more about Read Aloud
Yes! You can use the Perlego app on both iOS and Android devices to read anytime, anywhere — even offline. Perfect for commutes or when you’re on the go.
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Yes, you can access Artificial Intelligence and Deep Learning in Pathology by Stanley Cohen in PDF and/or ePUB format, as well as other popular books in Medicine & Pathology. We have over one million books available in our catalogue for you to explore.