Physics of Data Science and Machine Learning links fundamental concepts of physics to data science, machine learning, and artificial intelligence for physicists looking to integrate these techniques into their work.
This book is written explicitly for physicists, marrying quantum and statistical mechanics with modern data mining, data science, and machine learning. It also explains how to integrate these techniques into the design of experiments, while exploring neural networks and machine learning, building on fundamental concepts of statistical and quantum mechanics.
This book is a self-learning tool for physicists looking to learn how to utilize data science and machine learning in their research. It will also be of interest to computer scientists and applied mathematicians, alongside graduate students looking to understand the basic concepts and foundations of data science, machine learning, and artificial intelligence.
Although specifically written for physicists, it will also help provide non-physicists with an opportunity to understand the fundamental concepts from a physics perspective to aid in the development of new and innovative machine learning and artificial intelligence tools.
Key Features:
Introduces the design of experiments and digital twin concepts in simple lay terms for physicists to understand, adopt, and adapt.
Free from endless derivations; instead, equations are presented and it is explained strategically why it is imperative to use them and how they will help in the task at hand.
Illustrations and simple explanations help readers visualize and absorb the difficult-to-understand concepts.
Ijaz A. Rauf is an adjunct professor at the School of Graduate Studies, York University, Toronto, Canada. He is also an associate researcher at Ryerson University, Toronto, Canada and president of the Eminent-Tech Corporation, Bradford, ON, Canada.
1.1 A Physicist’s View of the Natural World and Probabilities
Physicists aim to find a single theory that can explain the whole universe, but to do so, they must solve some of the most challenging problems of science. Before Newton, a physicist’s view of the world was only two-dimensional. By introducing gravity, Newton enabled us to pass from a picture with two-dimensional symmetry to a picture with three-dimensional symmetry. Building on this, Einstein expanded this three-dimensional view of the world to a four-dimensional view by introducing the time domain. The time domain was introducing the particular theory of relativity that considers the four-dimensional world view to be linear. Einstein further expanded this view by proposing relativity’s general theory, where the space–time continuum is curved (or nonlinear). The general theory of relativity helps explain most of the physical phenomenon; however, it fails when phenomenon at microscopic scales (atomic scales) is considered. The atomic-scale phenomenon is the area that leads to the emergence of the quantum theory, and it pertains to the discussion of tiny things – subatomic phenomenon.
The quantum theory first emerged when Planck realized the need to conclude that electromagnetic waves’ energy can only occur in multiples of a certain amount; this depended on the waves’ frequency to justify the law of black-body radiation. Then, Einstein discovered that the same energy unit occurs in the photoelectric effect. Bohr’s atomic model provided an incomplete and very primitive picture of the physical world on a small scale. The quantum theory’s significant breakthrough came in 1925 when quantum mechanics was advanced by Heisenberg and Schrodinger independently. This development resulted in a dramatic shift in the image of the universe by the physicist because we had to give up the deterministic image that we often took for granted. We are guided to a hypothesis that does not predict with certainty what is expected to happen in the future but instead gives us knowledge about the likelihood (probability) of occurrence of different events.
Physicists are used to working with massive amounts of data, but they are lucky because their experimental data are of very high quality. The advent of big data has resulted in an influx of data sets with a much more complicated structure – a trend needing new methods and a different mindset. The growth of big data offers an opportunity for physicists. Nevertheless, they need a slight yet necessary change in attitude to take full advantage. Physicists like to think they understand the data to figure out the causal relationships between events; they have scientific methods, mathematical tools, and analytical knowledge. Some data structures are more complex than others. However, if correctly performed, well-designed experiments produce clean data that can be analyzed to draw simple, empirical conclusions about nature’s inner workings. However, this is exceptionally wishful thinking as it tends to downplay the role of experimental design.
The experimental design is where physicists excel by working in a natural system where clean experiments are possible. A strong understanding of calculus, arithmetic, and programming helps. Physicists are comparatively superior from a technological viewpoint compared with their colleagues in other natural sciences. The truth is that statisticians, computer scientists, biologists, psychologists, and economists frequently lack the privilege of working with clean data.
An increasing number of problems come in a shape opposite of what physicists are used to seeing, for example, to evaluate user experiences on individual websites or social media or assess epidemics’ dynamics to determine the consequences of economic policy, which can be quantified meaningfully. These are situations where “experiments” are far from optimal but relatively easy to conduct and generate data streams with an incredibly complex structure.
Physicists must learn a new lexicon to translate their expertise to be useful in new unknown circumstances. An essential move in this process is to acknowledge that while models have a high degree of applicability to evaluate large-scale data sets, their use is just one approach. Physicists tend to opt for generative models, namely those that allow synthetic data generation before any observation. Nevertheless, a depiction of nature relies on numerous assumptions and approximations. In comparison, discriminative models do not have a mechanism for generating the data. These are based on a series of techniques that view the experimental data as a direct input, which is then used to refine the fitting model iteratively. This method is possible thanks to Bayes’ theorem.
There is also plenty that physicists can learn from modern statistics and probability, and the information theory. Complemented by a few primary principles from these disciplines, the techniques already mastered by physicists from statistical mechanics and field theory can be adapted for use in the most complex data analysis tasks facing other disciplines of science. It may be surprising that mathematical techniques initially developed in physics, including those necessary to calculate the partition function, were transferred and further developed into other research domains. It is time that physicists to learn and reclaim these advancements.
1.2 Data – Types of Data
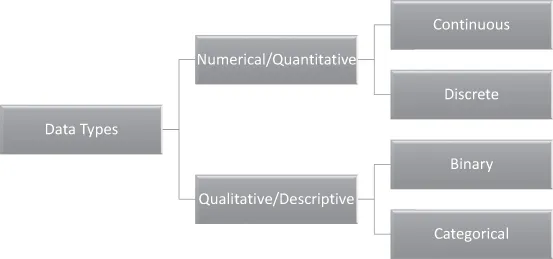
Humans have collected, processed, and analyzed data from time immemorial without developing a name for this. It was 1640 when the word “data” first appeared in the English language when physicists realized that the material systems are better understood when described in a small number of parameters. Values prescribed for these parameters became to be known as data. Data can broadly be divided into two main classes: quantitative and qualitative data. Both can be further divided into two subclasses, as shown in Figure 1.1. The quantitative data could be continuous, where it could be measured on an infinitely divisible scale provided we have sensitive enough measuring equipment. For example, the distance between two points, the length, and height of an object are all examples of continuous data. Alternatively, it could be discrete when it can only have specific values, such as the number of students in the class and the number of electrons in an atom.
FIGURE1.1 Various classifications of data.
On the other hand, the qualitative data can be either binary. It can have only one of the two prescribed values: the charge on a particle (positive or negative) and exam result (pass or fail). Alternatively, it could be an attribute, for example, color, religion, or nationality.
1.2.1 Data to Information
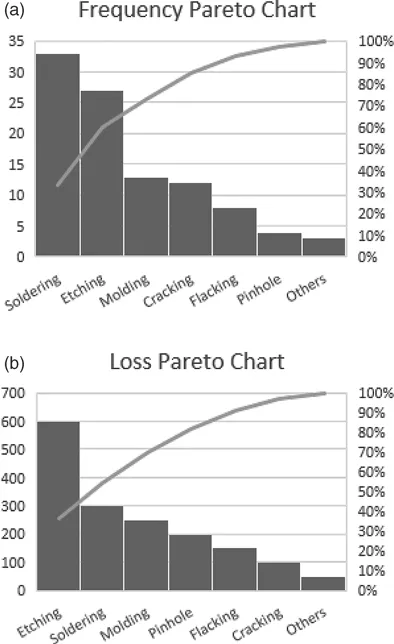
One may drive some meanings from given data itself when there is only a small amount of data. As the amount of data starts to increase, it becomes increasingly difficult to derive meaning from the data. Table 1.1 shows data from a semiconductor manufacturing line showing various causes for chip failure. Data in its raw form require a bit of human effort to sort through and get the information. However, if these data are transformed into Pareto charts, as shown in Figure 1.2, significant information becomes readily available for decision-making by the observer.
The term “information” is defined as the data presented in context, structured, organized, and processed, making it meaningful and useful to the individual who needs it. Data mean raw facts and statistics about people, locations, or something else represented as numbers, letters, or symbols.
Information is the converted and classified data into an intelligible form that can be used in the decision-making process. In short, when the data after processing turn out to be significant, it is called knowledge. In essence, it is something that tells; it addresses a particular query.
TABLE1.1 Data from a Semiconductor Chip Manufacturing Line
Defect Type
Frequency (Count)
Loss Per Defect ($)
Cracking
12
100
Soldering
33
300
Others
3
50
Etching
27
600
Pinhole
4
200
Flacking
8
150
Molding
13
250
FIGURE1.2 Data from Table 1.1 transformed into information for the observer for better decision-making.
Accuracy, relevance, completeness, and availability are the key features of the knowledge. It can be conveyed in the form of a message text or by observation. It can be obtained from various sources such as newspapers, television, the internet, people, and books.
As the amount of data increases, the transformation required to derive information from the data for meaningful decision-making becomes increasingly complex and challenging, requiring advanced statistical and graphical tools. A large amount of information can be transformed into knowledge by understanding the underlying relationships that help generalize the formulae or the theoretical framework for the phenomenon that generated the data. Converting information to useful knowledge is even more difficult and complicated, requiring tools to develop models for the systems under observation.
1.2.2 Information to Knowledge
Knowledge means a person’s insight and understanding, location, activities, thoughts, queries, ways of doing things, or something learned through studying, perceiving, or discovering. This new learning is the state of cognizance, recognizing something through the comprehension of concepts, research, and experience.
In short, information connotes an entity’s firm theoretical or realistic understanding, along with its ability to use it for a specific reason. A combination of information, experience, and intuition leads to knowledge that can draw inferences and develop insights based on our expertise. This knowledge also helps in decision-making and action-taking.
1.2.3 Critical Differences between Information and Knowledge
The points given below are essential. The difference between information and knowledge is concerned: The information denotes the organized data about someone or something obtained from various sources such as newspapers, the internet, television, and discussions. Knowledge refers to the understanding or comprehension of the acquired subject from a person’s education or experience. Knowledge is nothing but the distilled data type that helps to understand the context. Knowledge, on the other hand, is the appropriate and objective information that helps to conclude.
Information is generated by data gathered within the appropriate context. Conversely, it results in knowledge when the information is paired with experience and intuition. Processing enhances the representation, thus ensuring a simple understanding of the information; despite this, processing results in enhanced knowledge, thereby increasing the subject’s understanding. The information helps comprehend the facts and figures, unlike the knowledge that contributes to the subject’s understanding. The transmission of information is secure by different means, that is, verbal or nonverbal signals. Conversely, knowledge transfer is a little complicated, as it requires the user to develop an understanding.
Information can be reproduced at a low cost. However, precisely similar knowledge reproduction is not possible because it is based on experiential or individual values and perceptions. It is not enough to use information alone to make generalizations or predictions about someone or something. Knowledge may, on the contrary, predict or draw inferences. Every piece of information is not necessarily a piece of knowledge, but all knowledge is based on information.
1.3 Data Mining for Knowledge
As the name goes, the process of data mining could be understood by comparing it to traditional mining operations, where we dig through vast amounts of dirt and stones to find the gems hidden deep down. Data mining is thus the process of digging through a sea of raw data to discover new and previously unknown insights and information. Data mining is part of a more comprehen...
Table of contents
Cover
Half Title
Title Page
Copyright Page
Table of Contents
Dedication
Preface: Motivation and Rationale
Author
1 Introduction
2 An Overview of Classical Mechanics
3 An Overview of Quantum Mechanics
4 Probabilistic Physics
5 Design of Experiments and Analyses
6 Basics of Machine Learning
7 Prediction, Optimization, and New Knowledge Development
References
Index
Frequently asked questions
Yes, you can cancel anytime from the Subscription tab in your account settings on the Perlego website. Your subscription will stay active until the end of your current billing period. Learn how to cancel your subscription
No, books cannot be downloaded as external files, such as PDFs, for use outside of Perlego. However, you can download books within the Perlego app for offline reading on mobile or tablet. Learn how to download books offline
Perlego offers two plans: Essential and Complete
Essential is ideal for learners and professionals who enjoy exploring a wide range of subjects. Access the Essential Library with 800,000+ trusted titles and best-sellers across business, personal growth, and the humanities. Includes unlimited reading time and Standard Read Aloud voice.
Complete: Perfect for advanced learners and researchers needing full, unrestricted access. Unlock 1.4M+ books across hundreds of subjects, including academic and specialized titles. The Complete Plan also includes advanced features like Premium Read Aloud and Research Assistant.
Both plans are available with monthly, semester, or annual billing cycles.
We are an online textbook subscription service, where you can get access to an entire online library for less than the price of a single book per month. With over 1 million books across 990+ topics, we’ve got you covered! Learn about our mission
Look out for the read-aloud symbol on your next book to see if you can listen to it. The read-aloud tool reads text aloud for you, highlighting the text as it is being read. You can pause it, speed it up and slow it down. Learn more about Read Aloud
Yes! You can use the Perlego app on both iOS and Android devices to read anytime, anywhere — even offline. Perfect for commutes or when you’re on the go. Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Yes, you can access Physics of Data Science and Machine Learning by Ijaz A. Rauf in PDF and/or ePUB format, as well as other popular books in Computer Science & Computer Science General. We have over one million books available in our catalogue for you to explore.