
- 576 pages
- English
- ePUB (mobile friendly)
- Available on iOS & Android
Machine Learning Engineering in Action
About this book
Field-tested tips, tricks, and design patterns for building machine learning projects that are deployable, maintainable, and secure from concept to production. In Machine Learning Engineering in Action, you will learn: Evaluating data science problems to find the most effective solution
Scoping a machine learning project for usage expectations and budget
Process techniques that minimize wasted effort and speed up production
Assessing a project using standardized prototyping work and statistical validation
Choosing the right technologies and tools for your project
Making your codebase more understandable, maintainable, and testable
Automating your troubleshooting and logging practices Ferrying a machine learning project from your data science team to your end users is no easy task. Machine Learning Engineering in Action will help you make it simple. Inside, you'll find fantastic advice from veteran industry expert Ben Wilson, Principal Resident Solutions Architect at Databricks. Ben introduces his personal toolbox of techniques for building deployable and maintainable production machine learning systems. You'll learn the importance of Agile methodologies for fast prototyping and conferring with stakeholders, while developing a new appreciation for the importance of planning. Adopting well-established software development standards will help you deliver better code management, and make it easier to test, scale, and even reuse your machine learning code. Every method is explained in a friendly, peer-to-peer style and illustrated with production-ready source code. About the technology
Deliver maximum performance from your models and data. This collection of reproducible techniques will help you build stable data pipelines, efficient application workflows, and maintainable models every time. Based on decades of good software engineering practice, machine learning engineering ensures your ML systems are resilient, adaptable, and perform in production. About the book
Machine Learning Engineering in Action teaches you core principles and practices for designing, building, and delivering successful machine learning projects. You'll discover software engineering techniques like conducting experiments on your prototypes and implementing modular design that result in resilient architectures and consistent cross-team communication. Based on the author's extensive experience, every method in this book has been used to solve real-world projects. What's insideScoping a machine learning project for usage expectations and budget
Choosing the right technologies for your design
Making your codebase more understandable, maintainable, and testable
Automating your troubleshooting and logging practices About the reader
For data scientists who know machine learning and the basics of object-oriented programming. About the author
Ben Wilson is Principal Resident Solutions Architect at Databricks, where he developed the Databricks Labs AutoML project, and is an MLflow committer.
Tools to learn more effectively

Saving Books

Keyword Search

Annotating Text

Listen to it instead
Information
Part 1 An introduction to machine learning engineering
1 What is a machine learning engineer?
- The scope of knowledge and skills for machine learning engineers
- The six fundamental aspects of applied machine learning project work
- The functional purpose of machine learning engineers
1.1 Why ML engineering?
Table of contents
- inside front cover
- Machine Learning Engineering in Action
- Copyright
- contents
- front matter
- Part 1 An introduction to machine learning engineering
- 1 What is a machine learning engineer?
- 2 Your data science could use some engineering
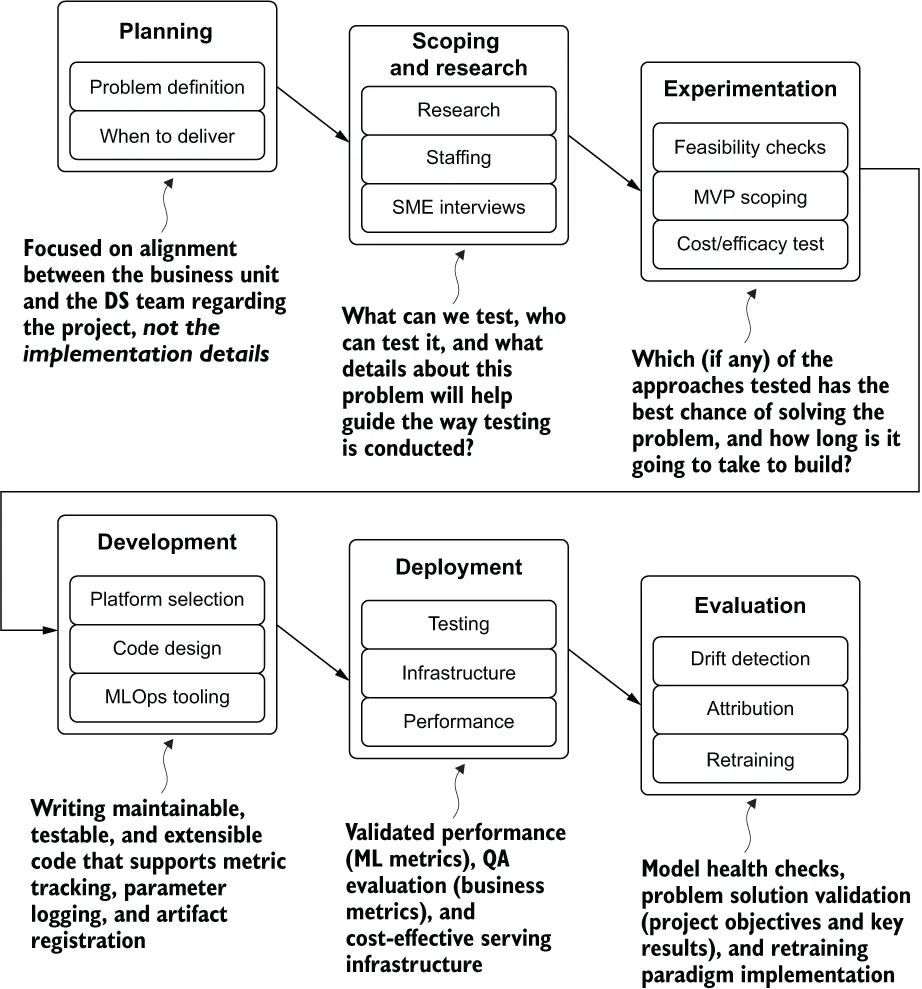
- 3 Before you model: Planning and scoping a project
- 4 Before you model: Communication and logistics of projects
- 5 Experimentation in action: Planning and researching an ML project
- 6 Experimentation in action: Testing and evaluating a project
- 7 Experimentation in action: Moving from prototype to MVP
- 8 Experimentation in action: Finalizing an MVP with MLflow and runtime optimization
- Part 2 Preparing for production: Creating maintainable ML
- 9 Modularity for ML: Writing testable and legible code
- 10 Standards of coding and creating maintainable ML code
- 11 Model measurement and why it’s so important
- 12 Holding on to your gains by watching for drift
- 13 ML development hubris
- Part 3 Developing production machine learning code
- 14 Writing production code
- 15 Quality and acceptance testing
- 16 Production infrastructure
- Appendix A. Big O(no) and how to think about runtime performance
- Appendix B. Setting up a development environment
- index
- inside back cover
Frequently asked questions
- Essential is ideal for learners and professionals who enjoy exploring a wide range of subjects. Access the Essential Library with 800,000+ trusted titles and best-sellers across business, personal growth, and the humanities. Includes unlimited reading time and Standard Read Aloud voice.
- Complete: Perfect for advanced learners and researchers needing full, unrestricted access. Unlock 1.4M+ books across hundreds of subjects, including academic and specialized titles. The Complete Plan also includes advanced features like Premium Read Aloud and Research Assistant.
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app