
- 214 pages
- English
- ePUB (mobile friendly)
- Available on iOS & Android
eBook - ePub
Causal Inferences in Nonexperimental Research
About this book
Taking an exploratory rather than a dogmatic approach to the problem, this book pulls together materials bearing on casual inference that are widely scattered in the philosophical, statistical, and social science literature. It is written in nonmathematical terms, and it is imaginative and sophisticated from both a theoretical and a statistical point of view.
Originally published in 1964.
A UNC Press Enduring Edition -- UNC Press Enduring Editions use the latest in digital technology to make available again books from our distinguished backlist that were previously out of print. These editions are published unaltered from the original, and are presented in affordable paperback formats, bringing readers both historical and cultural value.
Originally published in 1964.
A UNC Press Enduring Edition -- UNC Press Enduring Editions use the latest in digital technology to make available again books from our distinguished backlist that were previously out of print. These editions are published unaltered from the original, and are presented in affordable paperback formats, bringing readers both historical and cultural value.
Tools to learn more effectively

Saving Books

Keyword Search

Annotating Text

Listen to it instead
Information
V
Complicating Factors
In previous chapters the necessity of imposing a number of simplifying assumptions has been emphasized. We have assumed one-way causation, linear and additive models, the absence of confounding effects from outside variables, and negligible measurement errors. It has also been necessary to include in the theoretical system only those variables that have been directly linked with operational procedures. Many of these assumptions are highly restrictive. We must now raise important questions as to how we would proceed if one or more of these assumptions could be relaxed.
It would be highly encouraging if lifting these restrictions would lead to more or less straightforward extensions. Unfortunately, however, this does not appear to be the case. The social sciences are severely handicapped by the inability to experiment, imprecise measurements, and the difficulty in finding isolated systems for which the number of variables can be sharply delimited. We have already briefly mentioned certain problems encountered when one allows for reciprocal causation. We saw that coefficients may become unidentifiable unless additional information can be supplied. Likewise, we mentioned the problem of interaction for which nonadditive models would be more appropriate.
In the present chapter we shall discuss certain possible lines of attack on relatively simple problems where we must deal with (1) distortions produced by outside confounding influences, (2) unknown random and nonrandom measurement errors, and (3) models in which some of the variables must be taken as unmeasured. In each case we shall encounter rather formidable problems for which there appear to be no simple solutions. The approaches we shall suggest are obviously highly exploratory and as yet have not been applied to realistic problems.
Let us turn first to confounding influences. Later discussions of measurement errors and unmeasured variables will make use of similar approaches. The general strategy will he to conceive of confounding influences, measurement errors, and unmeasured variables in terms of specific causal models in which we include not only the measured variables of direct interest but also unknown or unmeasured variables which may be taken as the sources of confounding effects or measurement error. Certain of the variables included in the causal model will in each case be unmeasured, and our task will be to make inferences that either bypass or involve controls for these unmeasured variables.
REDUCING THE EFFECTS OF CONFOUNDING INFLUENCES
The scientific method can be viewed from the standpoint of the necessity of convincing the skeptic, who may raise a number of questions about the findings of any piece of research. Some of these questions may be illegitimate in the sense that they cannot possibly be answered definitively or even in probability terms. But others may be quite proper. One such question, which will be the focus of the present section, concerns the possibility that a relationship between two variables may be affected by an unknown third variable. Perhaps a social scientist has found a relationship that he asserts to be causal and not spurious. The study may or may not have been strictly experimental. Presumably, the investigator wants to establish that some independent variable X is an important cause of a dependent variable Y. He reports that as X is changed experimentally, Y tends to change also. Or he finds a high correlation between the two variables. The results are tested for significance, and it is found that it would be highly unlikely that they would occur under the null hypothesis of absolutely no relationship. But the skeptic may always raise the possibility that had some other variable been controlled, the results would have been otherwise.
In a sense, the objection of the skeptic is unfair if stated in vague terms. For no matter how careful the study, it is always possible to assert that some unknown and mysterious variable, which has been uncontrolled, is operating as a confounding influence in the sense that it is upsetting the “true” relationship between X and Y. Furthermore, it will be empirically impossible to show such an objection to be false. There is a burden on the skeptic at least to name the confounding influence involved, and ideally he should attempt to measure it and design an alternative study in which the presumed confounding influence is controlled.
But the entire burden should not be on the skeptic, whose question is basically quite legitimate. In the social sciences there are obviously large numbers of intercorrelated variables that are spuriously related, and as pointed out previously one of our most difficult and important tasks is to find valid ways of ignoring the myriad of spuriously intercorrelated variables in favor of the much smaller number of meaningful causal relationships. It therefore is of paramount importance to anticipate this particular kind of objection of the skeptic and to reduce the number of confounding influences to a minimum. There are, of course, several well-known methods for doing this, and we need only mention these briefly.
Let us take as our prototype of confounding influences the simple causal situation represented in Figure 14, where V and Z are operating (jointly) to produce a spurious relationship between a supposedly independent variable X and the dependent variable Y. This is in contrast with Figure 15, where T and U are taken as additional causes of Y but are assumed unrelated to X. In this latter situation, T and U will produce variation in Y, but this variation will be independent of that caused by X and, from the standpoint of the investigator, can be taken as random.
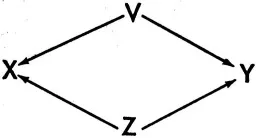
FIGURE 14
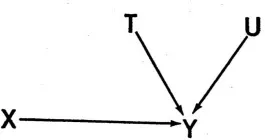
FIGURE 15
One of the most desirable ways of eliminating the effects of confounding influences is to introduce explicit controls for these variables. There seems to be little disagreement about this point, although we should perhaps emphasize R. A. Fisher’s argument that the application of several simultaneous controls for factors such as V and Z may be highly inefficient from the standpoint of cost considerations.1 The obvious difficulty, in addition, is that such confounding influences may not even be identified, much less easily measured.
Fisher’s alternative, of course, is randomization. In contrast with the first alternative involving rigid controls for confounding influences, we have seen that randomization does not control for these variables. But it makes them independent of X, except for sampling errors that can be evaluated in probability terms. Through randomization, variables such as V and Z are transformed into factors such as T and U. They continue to operate on Y, but they do not systematically affect the estimate of the relationship between X and Y, as measured by a slope. Since they continue to produce sampling error, however, randomization is in one sense a poor man’s substitute for rigid controlling procedures.
A third type of alternative is to change the nature of the design, ideally as much as possible, and to replicate the study. For example, certain types of confounding influences in experimental studies may have only short-run effects (e.g., memory effects owing to repeated testing). Others may not operate over short periods (e.g., effects of major outside events). Hopefully, if both long-term and short-term experiments give very similar results, we might infer the nonexistence of these particular types of confounding influences.
Better still, the results of experimental studies might be contrasted with comparative studies involving data collected at a single point in time. It is sometimes believed that change studies are generally superior to comparative ones. It is true that change studies may give insights into temporal sequences, but another apparent advantage is in the superior control over confounding influences. There is the suspicion that these latter influences may be more operative in comparative studies. However, this all depends on how many variables are changing at once. Obviously, change studies involving large numbers of variables, all of which are changing more or less simultaneously, admit the possibility of numerous confounding influences. But we will have additional faith in the conclusions if two studies, one of which involves change data and the other comparative data, both give similar results. Presumably, the same confounding influences are less likely to be operative in both studies.
Obviously there is no single procedure that will always guarantee the elimination of all confounding influences, and it will therefore be impossible to counter the skeptic’s objections in a completely definitive way. The investigator is always limited by funds and available knowledge and therefore seldom will be in a position to make use of alternative designs. The procedure we shall suggest should be evaluated in the same light. It will not always work, nor will it be feasible in all pieces fo research. It is merely one among a number of possible alternatives for reducing the effects of confounding influences. But in view of the fact that one of the social scientist’s most thorny problems is to eliminate such variables, we need to examine as carefully as possible the potentialities of whatever techniques we have.
Grouping and Confounding Influences. In the present section we shall deal with what appears to be a new technique for reducing the effects of confounding influences. The discussion will be limited to the rationale of the method, which will be applied to some artificially constructed data. Its full implications, especially as applied to real data, remain to be explored.
Basically, the procedure involves artificial manipulation of the data in such a way that the amount of variation in Y, the confounding influence, is reduced relative to the variation in the independent variable X. In other words, we attempt to hold the confounding influence as constant as possible, rather than to make it unrelated to the independent variable, as is accomplished through randomization. In essence, then, we treat the confounding influence as a control variable. But the principal advantage of the proposed technique over conventional controlling procedures is that we are not required to measure or even identify the disturbing influences. Ideally, the method can be used to reduce the effects of several confounding variables even when they are operating in completely unknown ways. In practice, however, it will be helpfu...
Table of contents
- Cover Page
- Title Page
- Copyright Page
- Dedication
- Contents
- Preface
- I INTRODUCTION
- II MATHEMATICAL REPRESENTATIONS OF CAUSAL MODELS
- III EVALUATING CAUSAL MODELS
- IV INFERENCES BASED ON CHANGES IN NONEXPERIMENTAL DESIGNS
- V COMPLICATING FACTORS
- VI SUMMARY AND CONCLUSIONS
- APPENDIX: SOME RELATED APPROACHES
- INDEX
Frequently asked questions
Yes, you can cancel anytime from the Subscription tab in your account settings on the Perlego website. Your subscription will stay active until the end of your current billing period. Learn how to cancel your subscription
No, books cannot be downloaded as external files, such as PDFs, for use outside of Perlego. However, you can download books within the Perlego app for offline reading on mobile or tablet. Learn how to download books offline
Perlego offers two plans: Essential and Complete
- Essential is ideal for learners and professionals who enjoy exploring a wide range of subjects. Access the Essential Library with 800,000+ trusted titles and best-sellers across business, personal growth, and the humanities. Includes unlimited reading time and Standard Read Aloud voice.
- Complete: Perfect for advanced learners and researchers needing full, unrestricted access. Unlock 1.4M+ books across hundreds of subjects, including academic and specialized titles. The Complete Plan also includes advanced features like Premium Read Aloud and Research Assistant.
We are an online textbook subscription service, where you can get access to an entire online library for less than the price of a single book per month. With over 1 million books across 990+ topics, we’ve got you covered! Learn about our mission
Look out for the read-aloud symbol on your next book to see if you can listen to it. The read-aloud tool reads text aloud for you, highlighting the text as it is being read. You can pause it, speed it up and slow it down. Learn more about Read Aloud
Yes! You can use the Perlego app on both iOS and Android devices to read anytime, anywhere — even offline. Perfect for commutes or when you’re on the go.
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Yes, you can access Causal Inferences in Nonexperimental Research by Hubert M. Blalock Jr. in PDF and/or ePUB format, as well as other popular books in Philosophy & Philosophy History & Theory. We have over one million books available in our catalogue for you to explore.