![]()
Chapter 1
Introduction
This book deals with machine learning (ML) and pattern recognition (PR). Even though humans can deal with both physical objects and abstract notions in day-to-day activities while making decisions in various situations, it is not possible for the computer to handle them directly. For example, in order to discriminate between a chair and a pen, using a machine, we cannot directly deal with the physical objects; we abstract these objects and store the corresponding representations on the machine. For example, we may represent these objects using features like height, weight, cost, and color. We will not be able to reproduce the physical objects from the respective representations. So, we deal with the representations of the patterns, not the patterns themselves. It is not uncommon to call both the patterns and their representations as patterns in the literature.
So, the input to the machine learning or pattern recognition system is abstractions of the input patterns/data. The output of the system is also one or more abstractions. We explain this process using the tasks of pattern recognition and machine learning. In pattern recognition there are two primary tasks:
1.Classification: This problem may be defined as follows:
•There are C classes; these are Class1, Class2, …, ClassC.
•Given a set Di of patterns from Classi for i = 1, 2, …, C. D = D1 ∪ D2 … ∪ DC. D is called the training set and members of D are called labeled patterns because each pattern has a class label associated with it. If each pattern Xj ∈ D is d-dimensional, then we say that the patterns are d-dimensional or the set D is d-dimensional or equivalently the patterns lie in a d-dimensional space.
•
A classification model
c is
learnt using the training patterns in
D.
•
Given an unlabeled pattern
X, assign an appropriate class label to
X with the help of
c.
It may be viewed as assigning a class label to an unlabeled pattern. For example, if there is a set of documents, Dp, from politics class and another set of documents, Ds, from sports, then classification involves assigning an unlabeled document d a label; equivalently assign d to one of two classes, politics or sports, using a classifier learnt from Dp ∪ Ds.
There could be some more details associated with the definition given above. They are
•A pattern Xj may belong to one or more classes. For example, a document could be dealing with both sports and politics. In such a case we have multiple labels associated with each pattern. In the rest of the book we assume that a pattern has only one class label associated.
•It is possible to view the training data as a matrix D of size n × d where the number of training patterns is n and each pattern is d-dimensional. This view permits us to treat D both as a set and as a pattern matrix. In addition to d features used to represent each pattern, we have the class label for each pattern which could be viewed as the (d + 1)th feature. So, a labeled set of n patterns could be viewed as {(X1, C1), (X2, C2), …, (Xn, Cn)} where Ci ∈ {Class1, Class2, …, ClassC} for i = 1, 2, …, n. Also, the data matrix could be viewed as an n × (d + 1) matrix with the (d + 1)th column having the class labels.
•
We evaluate the classifier learnt using a separate set of patterns, called
test set. Each of the
m test patterns comes with a class label called the
target label and is labeled using the classifier learnt and this label assigned is the
obtained label. A test pattern is correctly classified if the obtained label matches with the target
label and is
misclassified if they mismatch. If out of
m patterns,
mc are correctly classified then the % accuracy of the classifier is
•In order to build the classifier we use a subset of the training set, called the validation set which is kept aside. The classification model is learnt using the training set and the validation set is used as test set to tune the model or obtain the parameters associated with the model. Even though there are a variety of schemes for validation, K-fold cross-validation is popularly used. Here, the training set is divided into K equal parts and one of them is used as the validation set and the remaining K − 1 parts form the training set. We repeat this process K times considering a different part as validation set each time and compute the accuracy on the validation data. So, we get K accuracies; typically we present the sample mean of these K accuracies as the overall accuracy and also show the sample standard deviation along with the mean accuracy. An extreme case of validation is to consider n-fold cross-validation where the model is built using n−1 patterns and is validated using the remaining pattern.
2.Clustering: Clustering is viewed as grouping a collection of patterns. Formally we may define the problem as follows:
•There is a set, D, of n patterns in a d-dimensional space. A generally projected view is that these patterns are unlabeled.
•Partition the set D into K blocks C1, C2, …, CK; Ci is called the ith cluster. This means Ci ∩ Cj = ϕ and Ci ≠ ϕ for i ≠ j and i, j ∈ {1, 2, …, K}.
•In classification an unlabeled pattern X is assigned to one of C classes and in clustering a pattern X is assigned to one of K clusters. A major difference is that classes have semantic class labels associated with them and clusters have syntactic labels. For example, politics and sports are semantic labels; we cannot arbitrarily relabel them. However, in the case of clustering we can change the labels arbitrarily, but consistently. For example, if D is partitioned into two clusters C1 and C2; so the clustering of D is πD = {C1, C2}. So, we can relabel C1 as C2 and C2 as C1 consistently and have the same clustering (set {C1, C2}) because elements in a set are not ordered.
Some of the possible variations are as follows:
•In a partition a pattern can belong to only one cluster. However, in soft clustering a pattern may belong to more than one cluster. There are applications that require soft clustering.
•Even though clustering is viewed conventionally as partitioning a set of unlabeled patterns, there are several applications where clustering of labeled patterns is useful. One application is in efficient classification.
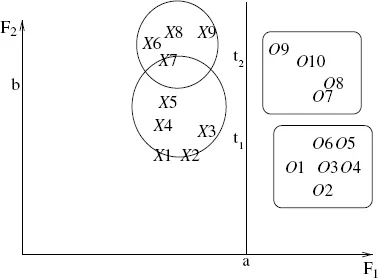
We illustrate the pattern recognition tasks using the two-dimensional dataset shown in Figure 1.1. There are nine points from class X labeled X1, X2, …, X9 and 10 points from class O labeled O1, O2, …, O10. It is possible to cluster patterns in each class separately. One such grouping is shown in Figure 1.1. The Xs are clustered into two groups and the Os are also clustered into two groups; there is no requirement that there be equal number of clusters in each class in general. Also we can deal with more than two classes. Different algorithms might generate different clusterings of each class. Here, we are using the class labels to cluster the patterns as we are clustering patterns in each class separately. Further we can represent each cluster by its centroid, medoid, or median which helps in data compression; it is sometimes adequate to use the cluster representatives as training data so as to reduce the training effort in terms of both space and time. We discuss a variety of algorithms for clustering data in later chapters.
Figure 1.1. Classification and clustering.
1.Classifiers: An Introduction
In order to get a feel for classification we use the same data points shown in Figure 1.1. We also considered two test points labeled t1 and t2. We briefly illustrate some of the prominent classifiers.
•Nearest Neighbor Classifier (NNC): We take the nearest neighbor of the test pattern and assign the label of the neighbor to the test pattern. For the test pattern t1, the nearest neighbor is X3; so, t1 is classified as a member of X. Similarly, the nearest neighbor of t2 is O9 and so t2 is assigned to class O.
•K-Nearest Neighbor Classifier (KNNC): We consider K-nearest neighbors of the test pattern and assign it to the class based on majority voting; if the number of neighbors from class X is more than that of class O, then we assign the test pattern to class X; otherwise to class O. Note that NNC is a special case of KNNC where K = 1.
In the example, if we consider three nearest neighbors of t1 then they a...