![]()
1Action Observation as a Visual Process: Different Classes of Actions Engage Distinct Regions of Human PPC
Guy A. Orban
Department of Neuroscience
University of Parma, Italy
This chapter is devoted to action observation i.e. the perception of the other’s actions, a topic generally neglected in vision, despite its ethological importance. It introduces a number of concepts related to action observation, formalizing the notion of action classes as the highest level of the identity description for observed actions (OA). After a review of the psychophysical study of one such action class, I show how the notion of action class illuminates the functional organization of the posterior parietal cortex (PPC), in that distinct regions are involved in processing different observed action classes. It also suggests that action observation, at least at the PPC level, can serve as substitute (proxy) for action execution, opening a new window onto the investigation of the action planning function of PPC. Finally, it also calls for a reappraisal of the role of mirror neurons in action observation and suggests that the exemplar level of OA identity may be coded by purely visual neurons, located within those various PPC regions.
1.Towards a Definition of Action Observation and its Psychophysical Testing
1.1.Defining action observation:
intrinsic aspects and extrinsic factors
Action observation refers to the process of visually assessing the goal of an action performed by conspecifics as well as how the movements of the effectors allow achieving that goal (Platonov and Orban, 2016). Thus, the visual processing of observed actions (OA) comprises two aspects: identity and parameters. The main aspect is the identity of the action which derives from the goal of the action and the manner to achieve that goal using natural effectors (body parts). What has so far been under-appreciated is that OA identity can be described at three levels at the least. The coarsest level is an action class, i.e. a set of actions which all have similar goals. The class of manipulation has as a goal the displacement in space and/or the deformation of objects. The class of locomotion directed towards moving the actor’s body through 3D space. The next level of observed action identity is represented by the action exemplars within a class or category. Typical exemplars of manipulation are grasping, dropping, pushing, dragging, rotating, but also squeezing or tearing apart. Typical exemplars of locomotion are walking and running, but also include climbing, swimming, crawling or jumping. For locomotion it may be the case that a further distinction has to be drawn between actions involving mainly the legs (walking) and actions involving all four limbs more or less equally (climbing or swimming). The third and lowest level is that of exemplar versions which are particular ways to perform a given exemplar action. The clearest examples are the different types of grasping, such as precision grip, whole-hand grip. These are typically associated to certain object shapes or object parts. In a similar vein, the different swimming strokes such as breast stroke, butterfly or free style can be considered versions of the action exemplar swimming. While the two lowest levels of description were readily recognized from the onset (Rizzolatti et al., 1987; Gallese et al., 1996), the notion of observed action class was recognized only very recently (Abdollahi et al., 2013). It should be distinguished from the semantic action categories that describe actions at a more abstract, conceptual level (Wurm et al., 2016). The present notion of action classes is directly related to sensorimotor transformations and behavioral repertoire, reminiscent of the work of Graziano and Aflalo (2007), Kaas and Stepniewska (2016).
The number of action classes included in the human repertoire is not clearly established. In fact, we have so far defined the classes more or less arbitrarily using the criterion that they should involve obviously different sensorimotor transformations. Indeed, the sensory information required for locomotion and manipulation are quite distinct. For locomotion, the layout of 3D space is important including obstacles, for manipulation, object properties such as size shape and weight seem more important. These classes in humans also use different effectors: manipulation hands or fingers, while locomotion use lower limbs or all four limbs. In addition to manipulation and locomotion, we have defined in this way other action classes such as vocal communication, direct and indirect communication using hands, skin displacing actions and interpersonal actions (Ferri et al., 2015; Urgen and Orban, 2016; Corbo and Orban, 2017). From this description, it is clear that the taxonomy of human actions is only in its infancy and one interesting avenue we are pursuing is to use the activity evoked in the brain to define the OA classes of the human action repertoire.
The second aspect of the visual processing of action concerns the parameters intrinsic to the action i.e. the effector used, the dynamics and the kinematics. We propose that the processing of the identity (class/exemplar/version) in action observation is performed predominantly at the level of the posterior parietal cortex (PPC), and the processing related to the parameters instead be a premotor function, without necessarily assuming a strict separation between the two aspects. This distinction concerning the visual processing has its basis in the differing contribution of these levels to the planning of actions, the PPC generating a much more general and preliminary plan than the premotor cortex. The same “motor” logic may explain the apparent paradox whereby the effector enters the definition of the action class, which we claim should be processed at the PPC level, while at the same time we also propose that the visual processing of the effectors represents a predominantly premotor function. This apparent contradiction can be resolved by considering that the preliminary plan in PPC includes the “typical” effector, which can be exchanged for a different effector, including an artificial one, once the plan is specified at the premotor level. Thus the typical effector enters the definition of the sensorimotor transformation corresponding to the action classes (Jastorff et al., 2010), which is used as a temporary filler.
The intrinsic aspects of observed actions should be carefully distinguished from other factors, which, although closely related and generally present in the scenes observed or the videos portraying actions, are not a part of the description of an observed action. The main extrinsic factor is of course the actor or agent, as there is no action without an agent. Yet, this is actually an extrinsic factor, insofar as the same action can be performed by many people while keeping its identity. The factor “actor” comes with many attachments. Some are easily dissociated from an observed action such as biological factors, e.g. age or gender, or motor aspects such as posture; but other more cognitive properties, such as intention or determination are more difficult to dissociate from the observed action, and are actually often attributed to the observed action (Gallivan et al., 2011; Palmer et al., 2016). Another extrinsic factor is the target of the action, which can be an object, a point in space, or a conspecific, depending on the action class. Objects that are manipulated can be especially difficult to dissociate from the action, as the lowest level of the identity, exemplar version, may be adjusted depending on the object or object part targeted. For example, the concrete level of actions in the study (Wurm and Lignau, 2015) mixed actions and objects, while their intermediate level of abstraction corresponded to the exemplar-version level of identity. In our studies, the factors object and actor are combined creating “variants” of the observed action (OA) exemplars, to investigate the invariance properties of the OA representations, and minimize the effects of low level factors. One last extrinsic factor which also necessarily participates in action observation is the observer, accompanied by optical qualities such as visual field, distance, and viewpoint. While these latter parameters are obviously extrinsic to the observed action, they greatly influence the neuronal structures in the observer’s brain involved in action observation.
It is remarkable that within the field of vision, action observation receives little mention. Any recent meeting of SFN or VSS is a testimony to this fact. There may be many reasons for this omission. One may be the tradition in psychology to deal with visual objects, which ironically include conspecifics, hence I have proposed (Orban et al., 2014) to use the term “real world entities (RWE)” rather than objects. Another factor might be the use of the term “action understanding” or “action recognition” by the Parma group (Gallese et al., 1996; Rizzolatti et al., 2014) when they were actually referring to action perception, rather than to the memory functions to which understanding or recognition are generally attributed (Caramazza et al., 2014). They avoided the obvious choice of other’s or observed action perception, because of their a priori contention that this capability reflected a motor and not a visual process. Yet we visually perceive actions of conspecifics as well as do an object, face or scene. Hence, I propose that action observation is part of visual perception. Once one has accepted that action observation is part of vision, it follows that it can be tested very much like other aspects of visual perception, by using discrimination tasks. This circumvents using complex tasks as in past studies (Clerget et al., 2009; Fazio et al., 2009; Michael et al., 2014; Vanuscorps and Caramazza, 2016), the interpretation of which is complicated by the many cognitive aspects associated with the processing of the identities of the observed actions they include. In fact, years ago I proposed the use of discrimination tasks such as identification, successive or simultaneous discrimination, as a way of simplifying the processing taking place in a complex brain (Orban et al., 1997), and as an alternative to studying small animal model brains.
1.2.Finally, a psychophysical study of action observation
In the past, I have extensively studied discriminations of simple visual features such as static orientation (Orban et al., 1984; Vogels and Orban, 1985), speed (De Bruyn and Orban, 1988) or direction of moving random dots in humans, macaques (Lauwers et al., 2000), and even cats (Vandenbussche et al., 1986), by manipulating parameter values to determine just noticeable differences (jnds). These thresholds are very attractive as they indicate the minimum difference that can be reliably reported, and hence provide an intuitive measure of how well subjects perceive a feature or how much they improve with training. In addition, they can be readily compared with similar measures for single neurons (Vogels and Orban, 1990; Schoups et al., 2001) or provide a clear picture of the deficit induced by lesions (Vogels et al., 1997). In trying to apply the same strategy to observed actions, it became clear that this implied warping between two action videos. While such a procedure is straight forward with static images of any complexity, this is not the case for videos, in which complex issues such as occlusions arise when trying to warp successive frames (Giese personal communication). Hence, we resorted to an alternative type of discrimination tasks using two very distinct discriminanda, here two observed actions, but limiting their visibility by either injecting dynamic noise or controlling the duration of presentation. The first strategy was particularly attractive as these sorts of data are well fitted by diffusion rate models (Palmer et al., 2005). Such models have a relatively simple neuronal interpretation in that they involve mainly two stages: one providing the sensory evidence and the second accumulating this evidence until a bound is met. Given the work of the groups of Newsome, Shadlen and Ungerleider, the neuroscience behind this two-stage model has a strong foundation in single cell recordings (Shadlen and Newsome, 1996; Gold and Shadlen, 2001), and more recently, fMRI (Heekeren et al., 2008).
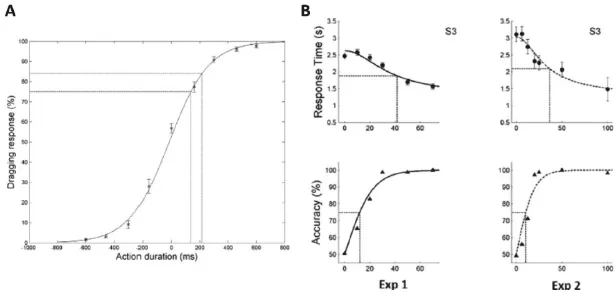
Figure 1 shows the performance of human subjects discriminating two observed manipulative actions (OMAs) in two alternative forced-choice (AFC) tasks. Figure 1(a) illustrates the percent right button responses as a function of the duration of the videos portraying the OMAs: as duration increases the percent correct responses, left for one OMA (negative values on ordinate) and right for the other (positive ordinate) increase. The data can be fitted by a logistic regression function and an accuracy threshold can be computed. Such tasks are now being used in functional imaging and intracerebral recording studies. Figure 1(b) illustrates alternative experiments in which visibility is limited by dynamic noise and subjects respond when ready, not at the end of the video (2.6s long) as in Fig. 1(a). Thus, we can plot both the reaction time and accuracy as a function of noise level. Since the subjects show hardly any bias (in Fig. 1(a), the zero % corresponds very closely to zero duration), we can fold the psychometric curve and plot accuracy ranging from 50% (chance) to 100%. These behavioral data, both RT and accuracy, are very closely fitted by the diffusion rate model (full line in Fig. 1(b)). Further evidence that the data is well-fitted by this model is provided by the ratio between the halfway RT and the halfway (75%) accuracy thresholds, which should equal 3.5, as was indeed the case (Platonov and Orban, 2016). Figure 1(b) also shows data from the same subject for discrimination of two different pairs of OMAs: observing rolling-rotating in experiment 1, and observing dragging and grasping in experiment 2. This demonstrates the generality of our findings for OMAs. At present, we are extending this experiment to other observed action classes.
Fig. 1.Psychometric curves for observed manipulative actions. (a) percent dragging responses as a function o...