
Apache Kafka Quick Start Guide
Leverage Apache Kafka 2.0 to simplify real-time data processing for distributed applications
- 186 pages
- English
- ePUB (mobile friendly)
- Available on iOS & Android
Apache Kafka Quick Start Guide
Leverage Apache Kafka 2.0 to simplify real-time data processing for distributed applications
About This Book
Process large volumes of data in real-time while building high performance and robust data stream processing pipeline using the latest Apache Kafka 2.0
Key Features
- Solve practical large data and processing challenges with Kafka
- Tackle data processing challenges like late events, windowing, and watermarking
- Understand real-time streaming applications processing using Schema registry, Kafka connect, Kafka streams, and KSQL
Book Description
Apache Kafka is a great open source platform for handling your real-time data pipeline to ensure high-speed filtering and pattern matching on the fly. In this book, you will learn how to use Apache Kafka for efficient processing of distributed applications and will get familiar with solving everyday problems in fast data and processing pipelines.
This book focuses on programming rather than the configuration management of Kafka clusters or DevOps. It starts off with the installation and setting up the development environment, before quickly moving on to performing fundamental messaging operations such as validation and enrichment.
Here you will learn about message composition with pure Kafka API and Kafka Streams. You will look into the transformation of messages in different formats, such asext, binary, XML, JSON, and AVRO. Next, you will learn how to expose the schemas contained in Kafka with the Schema Registry. You will then learn how to work with all relevant connectors with Kafka Connect. While working with Kafka Streams, you will perform various interesting operations on streams, such as windowing, joins, and aggregations. Finally, through KSQL, you will learn how to retrieve, insert, modify, and delete data streams, and how to manipulate watermarks and windows.
What you will learn
- How to validate data with Kafka
- Add information to existing data flows
- Generate new information through message composition
- Perform data validation and versioning with the Schema Registry
- How to perform message Serialization and Deserialization
- How to perform message Serialization and Deserialization
- Process data streams with Kafka Streams
- Understand the duality between tables and streams with KSQL
Who this book is for
This book is for developers who want to quickly master the practical concepts behind Apache Kafka. The audience need not have come across Apache Kafka previously; however, a familiarity of Java or any JVM language will be helpful in understanding the code in this book.
Frequently asked questions
Information
Accessing and Retrieving Data
- Viewing and analyzing M functions in the Query Editor
- Establishing and managing connections to data sources
- Building source queries for DirectQuery models
- Importing data to Power BI Desktop models
- Applying multiple filtering conditions
- Choosing columns and column names
- Transforming and cleansing source data
- Creating custom and conditional columns
- Integrating multiple queries
- Choosing column data types
- Visualizing the M library
Introduction
Viewing and analyzing M functions
Getting ready
- Build a query through the user interface that connects to the AdventureWorksDW2016CTP3 SQL Server database on the ATLAS server and retrieves the DimGeography table, filtered by United States for English.
- Click on Get Data from the Home tab of the ribbon, select SQL Server from the list of database sources, and provide the server and database names.
- For the Data Connectivity mode, select Import.
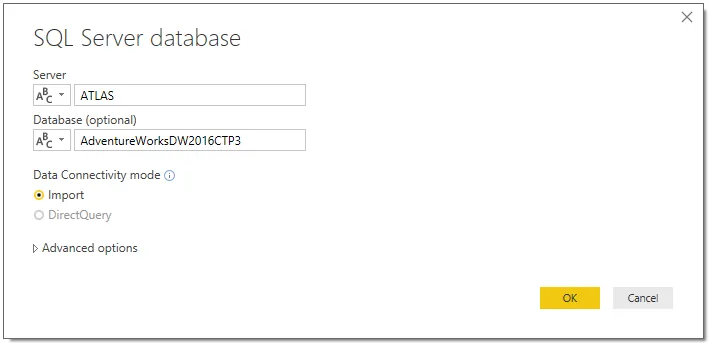
- In the Query Editor window, select the EnglishCountryRegionName column and then filter on United States from its dropdown.


How to do it...
Formula Bar
- With the Formula Bar visible in the Query Editor, click on the Source step under Applied Steps in the Query Settings pane.
- You should see the following formula expression:

- Click on the Navigation step to expose the following expression:

- The navigation expression (2) references the source expression (1)
- The Formula Bar in the...
Table of contents
- Title Page
- Copyright
- Credits
- Foreword
- About the Author
- About the Reviewers
- www.PacktPub.com
- Customer Feedback
- Preface
- Configuring Power BI Development Tools
- Accessing and Retrieving Data
- Building a Power BI Data Model
- Authoring Power BI Reports
- Creating Power BI Dashboards
- Getting Serious with Date Intelligence
- Parameterizing Power BI Solutions
- Implementing Dynamic User-Based Visibility in Power BI
- Applying Advanced Analytics and Custom Visuals
- Developing Solutions for System Monitoring and Administration
- Enhancing and Optimizing Existing Power BI Solutions
- Deploying and Distributing Power BI Content
- Integrating Power BI with Other Applications