
Hands-On Deep Learning with Apache Spark
Build and deploy distributed deep learning applications on Apache Spark
- 322 pages
- English
- ePUB (mobile friendly)
- Available on iOS & Android
Hands-On Deep Learning with Apache Spark
Build and deploy distributed deep learning applications on Apache Spark
About this book
Speed up the design and implementation of deep learning solutions using Apache Spark
Key Features
- Explore the world of distributed deep learning with Apache Spark
- Train neural networks with deep learning libraries such as BigDL and TensorFlow
- Develop Spark deep learning applications to intelligently handle large and complex datasets
Book Description
Deep learning is a subset of machine learning where datasets with several layers of complexity can be processed. Hands-On Deep Learning with Apache Spark addresses the sheer complexity of technical and analytical parts and the speed at which deep learning solutions can be implemented on Apache Spark.
The book starts with the fundamentals of Apache Spark and deep learning. You will set up Spark for deep learning, learn principles of distributed modeling, and understand different types of neural nets. You will then implement deep learning models, such as convolutional neural networks (CNNs), recurrent neural networks (RNNs), and long short-term memory (LSTM) on Spark.
As you progress through the book, you will gain hands-on experience of what it takes to understand the complex datasets you are dealing with. During the course of this book, you will use popular deep learning frameworks, such as TensorFlow, Deeplearning4j, and Keras to train your distributed models.
By the end of this book, you'll have gained experience with the implementation of your models on a variety of use cases.
What you will learn
- Understand the basics of deep learning
- Set up Apache Spark for deep learning
- Understand the principles of distribution modeling and different types of neural networks
- Obtain an understanding of deep learning algorithms
- Discover textual analysis and deep learning with Spark
- Use popular deep learning frameworks, such as Deeplearning4j, TensorFlow, and Keras
- Explore popular deep learning algorithms
Who this book is for
If you are a Scala developer, data scientist, or data analyst who wants to learn how to use Spark for implementing efficient deep learning models, Hands-On Deep Learning with Apache Spark is for you. Knowledge of the core machine learning concepts and some exposure to Spark will be helpful.
Tools to learn more effectively

Saving Books

Keyword Search

Annotating Text

Listen to it instead
Information
The Apache Spark Ecosystem
- Apache Spark fundamentals
- Getting Spark
- Resilient Distributed Dataset (RDD) programming
- Spark SQL, Datasets, and DataFrames
- Spark Streaming
- Cluster mode using a different manager
Apache Spark fundamentals

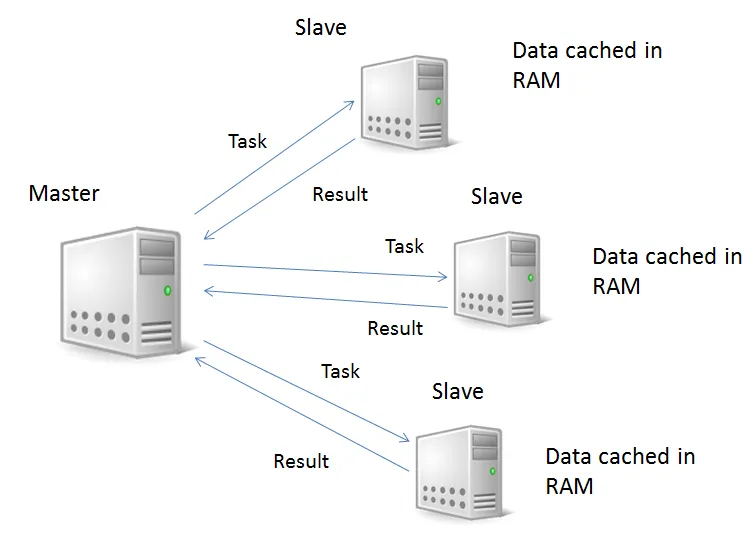
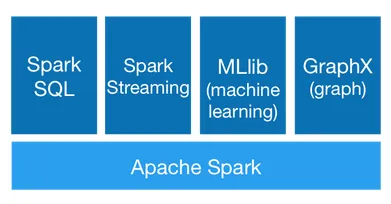
- The core engine.
- Spark SQL: A module for structured data processing.
- Spark Streaming: This extends the core Spark API. It allows live data stream processing. Its strengths include scalability, high throughput, and fault tolerance.
- MLib: The Spark machine learning library.
- GraphX: Graphs and graph-parallel computation algorithms.
Getting Spark

$SPARK_HOME/bin/spark-shell.sh
Spark context Web UI available at http://10.72.0.2:4040
Spark context available as 'sc' (master = local[*], app id = local-1518131682342).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.2.1
/_/
Using Scala version 2.11.8 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_91)
Type in expressions to have them evaluated.
Type :help for more information.
scala>

scala> spark.read.textFile("/usr/spark-2.2.1/examples/src/main/resources/people.txt")
res5: org.apache.spark.sql.Dataset[String] = [value: string] scala> res5.count()
res6: Long = 3
scala> res5.first()
res7: String = Michael, 29
Table of contents
- Title Page
- Copyright and Credits
- About Packt
- Contributors
- Preface
- The Apache Spark Ecosystem
- Deep Learning Basics
- Extract, Transform, Load
- Streaming
- Convolutional Neural Networks
- Recurrent Neural Networks
- Training Neural Networks with Spark
- Monitoring and Debugging Neural Network Training
- Interpreting Neural Network Output
- Deploying on a Distributed System
- NLP Basics
- Textual Analysis and Deep Learning
- Convolution
- Image Classification
- What's Next for Deep Learning?
- Appendix A: Functional Programming in Scala
- Appendix B: Image Data Preparation for Spark
- Other Books You May Enjoy
Frequently asked questions
- Essential is ideal for learners and professionals who enjoy exploring a wide range of subjects. Access the Essential Library with 800,000+ trusted titles and best-sellers across business, personal growth, and the humanities. Includes unlimited reading time and Standard Read Aloud voice.
- Complete: Perfect for advanced learners and researchers needing full, unrestricted access. Unlock 1.4M+ books across hundreds of subjects, including academic and specialized titles. The Complete Plan also includes advanced features like Premium Read Aloud and Research Assistant.
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app