
Apache Spark Quick Start Guide
Quickly learn the art of writing efficient big data applications with Apache Spark
- 154 pages
- English
- ePUB (mobile friendly)
- Available on iOS & Android
Apache Spark Quick Start Guide
Quickly learn the art of writing efficient big data applications with Apache Spark
About this book
A practical guide for solving complex data processing challenges by applying the best optimizations techniques in Apache Spark.
Key Features
- Learn about the core concepts and the latest developments in Apache Spark
- Master writing efficient big data applications with Spark's built-in modules for SQL, Streaming, Machine Learning and Graph analysis
- Get introduced to a variety of optimizations based on the actual experience
Book Description
Apache Spark is a flexible framework that allows processing of batch and real-time data. Its unified engine has made it quite popular for big data use cases. This book will help you to get started with Apache Spark 2.0 and write big data applications for a variety of use cases.
It will also introduce you to Apache Spark – one of the most popular Big Data processing frameworks. Although this book is intended to help you get started with Apache Spark, but it also focuses on explaining the core concepts.
This practical guide provides a quick start to the Spark 2.0 architecture and its components. It teaches you how to set up Spark on your local machine. As we move ahead, you will be introduced to resilient distributed datasets (RDDs) and DataFrame APIs, and their corresponding transformations and actions. Then, we move on to the life cycle of a Spark application and learn about the techniques used to debug slow-running applications. You will also go through Spark's built-in modules for SQL, streaming, machine learning, and graph analysis.
Finally, the book will lay out the best practices and optimization techniques that are key for writing efficient Spark applications. By the end of this book, you will have a sound fundamental understanding of the Apache Spark framework and you will be able to write and optimize Spark applications.
What you will learn
- Learn core concepts such as RDDs, DataFrames, transformations, and more
- Set up a Spark development environment
- Choose the right APIs for your applications
- Understand Spark's architecture and the execution flow of a Spark application
- Explore built-in modules for SQL, streaming, ML, and graph analysis
- Optimize your Spark job for better performance
Who this book is for
If you are a big data enthusiast and love processing huge amount of data, this book is for you. If you are data engineer and looking for the best optimization techniques for your Spark applications, then you will find this book helpful. This book also helps data scientists who want to implement their machine learning algorithms in Spark. You need to have a basic understanding of any one of the programming languages such as Scala, Python or Java.
Information
Spark RDD
-
- What is an RDD?
- How do you create RDDs?
- Different operations available to work on RDDs
- Important types of RDD
- Caching an RDD
- Partitions of an RDD
- Drawbacks of using RDDs
What is an RDD?
- Resilient: If we look at the meaning of resilient in the dictionary, we can see that it means to be: able to
recover quickly from difficult conditions.
Spark RDD has the ability to recreate itself if something goes wrong. You must be wondering, why does it need to recreate itself? Remember how HDFS and other data stores achieve fault tolerance? Yes, these systems maintain a replica of the data on multiple machines to recover in case of failure. But, as discussed in Chapter 1, Introduction to Apache Spark, Spark is not a data store; Spark is an execution engine. It reads the data from source systems, transforms it, and loads it into the target system. If something goes wrong while performing any of the previous steps, we will lose the data. To provide the fault tolerance while processing, an RDD is made resilient: it can recompute itself. Each RDD maintains some information about its parent RDD and how it was created from its parent. This introduces us to the concept of Lineage. The information about maintaining the parent and the operation is known as lineage. Lineage can only be achieved if your data is immutable. What do I mean by that? If you lose the current state of an object and you are sure that previous state will never change, then you can always go back and use its past state with the same operations, and you will always recover the current state of the object. This is exactly what happens in the case of RDDs. If you are finding this difficult, don't worry! It will become clear when we look at how RDDs are created.
Immutability also brings another advantage: optimization. If you know something will not change, you always have the opportunity to optimize it. If you pay close attention, all of these concepts are connected, as the following diagram illustrates:

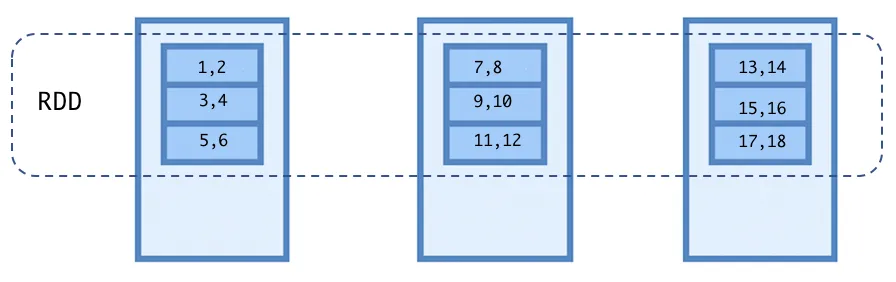
- Distributed: As mentioned in the following bullet point, a dataset is nothing but a collection of objects. An RDD can distribute its dataset across a set of machines, and each of these machines will be responsible for processing its partition of data. If you come from a Hadoop MapReduce background, you can imagine partitions as the input splits for the map phase.
- Dataset: A dataset is just a collection of objects. These objects can be a Scala, Java, or Python complex object; numbers; strings; rows of a database; and more.
Resilient metadata
- A list of parent RDD dependencies
- A function to compute a partition from the list of parent RDDs
- The preferred location for the partitions
- The partitioning information, in case of pair RDDs
Programming using RDDs
- Parallelize a collection: This is one of the easiest ways to create an RDD. You can use the existing collection from your programs, such as List, Array, or Set, as well as others, and ask Spark to distribute that collection across the cluster to process it in parallel. A collection can be distributed with the help of parallelize(), as shown here:
#Python
numberRDD = spark.sparkContext.parallelize(range(1,10))
numberRDD.collect()
Out[4]: [1, 2, 3, 4, 5, 6, 7, 8, 9]
//scala
val numberRDD = spark.sparkContext.parallelize(1 to 10)
numberRDD.collect()
res4: Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
- From an external dataset: Though parallelizing a collection is the easiest way to create an RDD, it is not the recommended way for the large datasets. Large datasets are generally stored on filesystems such as HDFS, and we know that Spark is built to process big data. Therefore, Spark provides a number of APIs to read data from the external datasets. One of the methods for reading external data is the textFile(). This method accepts a filename and creates an RDD, where each element of the RDD is the line of the input file.
//Scala
val filePath = "/FileStore/tables/sampleFile.log"
val logRDD = spark.sparkContext.textFile(filePath)
logRDD.collect()
res6: Array[String] = Array(2018-03-19 17:10:26 - myApp - DEBUG - debug message 1, 2018-03-19 17:10:27 - myApp - INFO - info message 1, 2018-03-19 17:10:28 - myApp - WARNING - warn message 1, 2018-03-19 17:10:29 - myApp - ERROR - error message 1, 2018-03-19 17:10:32 - myApp - CRITICAL - critical message with some error 1, 2018-03-19 17:10:33 - myApp - INFO - info message 2, 2018-03-19 17:10:37 - myApp - WARNING - warn message, 2018-0...
Table of contents
- Title Page
- Copyright and Credits
- About Packt
- Contributors
- Preface
- Introduction to Apache Spark
- Apache Spark Installation
- Spark RDD
- Spark DataFrame and Dataset
- Spark Architecture and Application Execution Flow
- Spark SQL
- Spark Streaming, Machine Learning, and Graph Analysis
- Spark Optimizations
- Other Books You May Enjoy
Frequently asked questions
- Essential is ideal for learners and professionals who enjoy exploring a wide range of subjects. Access the Essential Library with 800,000+ trusted titles and best-sellers across business, personal growth, and the humanities. Includes unlimited reading time and Standard Read Aloud voice.
- Complete: Perfect for advanced learners and researchers needing full, unrestricted access. Unlock 1.4M+ books across hundreds of subjects, including academic and specialized titles. The Complete Plan also includes advanced features like Premium Read Aloud and Research Assistant.
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app