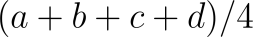![]()
RBM: Restricted Boltzmann Machine
The most prominent of all machine learning algorithms is RBM because it gave us the biggest breakthrough for developing neural networks by dealing with the vanishing gradient. Essentially, you have an input layer and a hidden layer with the input layer being the output layer. The hidden layer is only made up of a single set of neurons, which minimizes the amount of propagation. The important part here is that none of the nodes in the hidden layer share a connection to other nodes in the hidden layer. Training an RBM is a quick process due to these restrictions. The input is first sent to the hidden layer so that it can be transformed. After the data has been changed, a replacement of weights and/or biases is provided whether it be the same or different weights and/or biases. It is then sent back to the input layer, which has now become the output layer, to provide a reconstruction of that data. If the information is wrong, the weights and/or biases are adjusted until the reconstruction of the data is correct. RBM is part of the family known as Autoencoders and it works wonderfully with unlabeled data.
DBN: Deep Belief Network
As you can tell, from the last Deep Learning Algorithm, we haven’t explained how an RBM helped solve the vanishing gradient issue, which is where DBN comes in. DBN is a combination of RBM’s that have been put together on the same job but working on different tasks. DBNs are similar to MLPs in their structure, but they are completely the opposite when it actually comes down to training the neural network and that has to do with their implementation. Essentially, with a DBN you have RBM’s interconnected by making each hidden layer the input layer in succession. Therefore, let’s go over this in four steps. In step one, we add an input into the input layer. In step two, that input goes through its first RBM to become changed output. In step three, that hidden layer becomes the new input layer for the next RBM. This cycle repeats until it gets to the end. With each layer of RBM, the classifications are handling different parameters of the feature that require less and less abstraction of the data.
CNN: Convolutional Neural Networks
Convolutional neural networks are pretty much where most of the neural networking world is focused on. The reason being is because it is the forefront or the most newly discovered version of neural networking and it has a lot of applications. It has a lot of applications due to the fact that it can take unlabeled data, as the previous two did, and organize it into labeled data even if the data is changed slightly. Convolutional Networks actually work by utilizing two different Mathematical solutions. The first mathematical solution is filtering and filtering means that you use a mathematical equation to filter your results, such as finding the edges inside of a picture. Essentially, if an edge has a black color then you give it a 1, if it has a gray color then you give it at 0, and if it has a white color then you give it -1. A good example of a good filter would be multiplying every pixel value by the pixel value next to it. Whenever the pixels are black and black, you will always get a 1 and if they are white then you will get a 1. However, if you multiply 0 by -1 you get 0 and if you multiply 0 by 1 you get 0. This will tell the network that there is a difference in color there and so it will put that value there. The next mathematical solution comes from convolutional mathematics, which is to say that you are going to try all the different values over and over until you get to the end of trying all the values. The last part of the convolutional network is the filtering itself, which is to say that the data is then sectioned off into features so that it can examine specific blocks of the code. For instance, say you have a 40 x 40 grid of pixels. You would then use filtering to only go over every 10x10 pixels or 4x4 pixels to do your filtering. You use convolutional mathematics to try each of these filtered areas so as to provide a representative value of those areas. The center of each window of pixels, whatever size you choose, is then added up with each of the pixel values and divided by the number of pixels in the window size you choose. Therefore, if you choose a window of four pixels then it would be:
The final step in this convolutional process is to actually start at different locations inside of whatever you're looking at. Therefore, if you decided to start up at the left-hand corner and multiply everything on the right-hand side, then you would start at the right-hand corner and multiply by everything on the left side. You would do this for each of the possible directions that you have and then you would have several different images that have different numbers representing whatever you're looking at. These several different images represent the convolutional layer.
We're still not done though because this only represents the convolutional layer of the convolutional neural network. There are two more steps that are commonly used in convolutional neural networks, but they simply reduce the workload of the neural network themselves. This is where it's going to get confusing because we're going to do something called pooling. Pooling is the act of taking a specific size window, such as a 2x2 or a 4x4 pixel window and then selecting 2 or 4 pixels in which to move (known as a Stride) and going over each window of pixels in that image. Then you take the maximum values that you can obtain from each of those windows. If you get to a section that doesn’t have a complete window, you are still just going to take the maximum value. This can shrink the array down by nearly half, a third, or even a fourth of the original size. This is the section of a CNN that handles indiscriminate changes in an object or an image due to the fact that it’s still only going to take the maximum value. The last step in the changing process is to normalize the data or, rather, turn it all back to integers rather than doubles or floats and this just means you take all the negatives and put them as a null or a zero, otherwise known as RELU (Rectified Linear Units). All of this is then Deep Stacked, which is to say these final outputs become the new inputs until you get a tiny dataset at the end. Each of the values in the tiny set gets a judgment that serves as a prediction of whether something is one thing, another thing, or nothing. These are known as Votes and whoever gets the most of these will be the prediction. This guess is then you decide whether the network made an error or not. If it is wrong, the weights are changed where the network first went down the path of errors.
By doing this, you can take normal shapes that are a little bit wonky and still get a similar result even if they aren't exactly alike. For instance, if you took a car photo and applied a liquefying feature on it, the convolutional network would still end up with the same values, but they would be in slightly different places and so the convolutional network would still recognize the outline of the object and if it was close enough to match the outline that it already has in the neural network then it would be able to identify that object as the object you're trying to find. This makes convolutional neural networks absolutely vital when it comes to machine learning because it can take distorted data and recognize the patterns inside of it whereas a normal neural network would not be able to do this. The problem is that CNNs need to be supervised, which means that data needs to be collected and supplied to the CNN. This is a huge problem, especially when you think of it in terms of identifying faces. A good example of this problem is that Apple just recently got in trouble for claiming that it had trained its facial recognition software by utilizing over one billion faces. The obvious question, asked by a Senator in the U.S., was “Where did you get these?” and this now becomes an explosive privacy issue.
Perceptron: IMPORTANT!!!!
I know that this could have been included in a previous section but I wanted to wait until we got to talking about the different types of algorithms that networks can use because we need to talk about the one that started it all. The Perceptron was the very first and simplest neural network ever created. The best part about the Perceptron was that it was extremely simple to understand. It would take in an immeasurable amount of inputs and always produce either a one or a negative one. This is where you're going to learn how your neuron works. Essentially, imagine you have however many inputs you have going into a singular neuron that is then connected to the output. The output will be your prediction and the inputs will b...