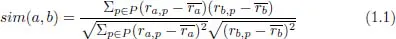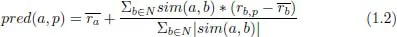![]()
Chapter 1
Collaborative Filtering: Matrix Completion and Session-Based Recommendation Tasks
Dietmar Jannacha and Markus Zankerb
This chapter provides a self-contained overview on the basics of collaborative filtering recommender systems. It covers two main classes of recommendation scenarios. In the classical matrix completion problem formulation, the task of an algorithm is to make longer-term relevance predictions given a user-item rating matrix. In session-based recommendation scenarios, the goal is to predict relevant items given a user’s observed short-term behavior. From an algorithmic perspective, the chapter particularly focuses on neighborhood-based methods, which were proposed in the early days of collaborative filtering and which are still relevant today. The chapter addresses the entire life-cycle of algorithm development and also discusses libraries, datasets, and implementation aspects. Furthermore, it covers evaluation issues and reflects on today’s research methodology in the field. Overall, the chapter shall serve as a starting point for readers, providing pointers to more detailed discussion of the various aspects regarding the design and evaluation of collaborative filtering recommender systems.
1.1.Introduction
Collaborative filtering (CF) is the predominant technical approach in the field of recommender systems in the academic literature (Jannach et al., 2012). It is also utilized by large companies in productive use since clearly more than 15 years, with the system of Amazon.com being one of the most prominent early examples of wide-scale deployment (Linden et al., 2003). The basic idea of this class of algorithms is to exploit the “wisdom of the crowds” and to use patterns within the collective behavior of a larger user community to determine suitable recommendations for an individual user or in the context of a given reference item.
In contrast to other possible approaches to determine recommendations, collaborative filtering techniques do not rely on content features and metadata of the items when determining the relevance of a recommendable item for a user like content-based or knowledge-based recommendation strategies (Jannach et al., 2011). In its pure form1, collaborative-filtering relies solely on a collection of explicit or implicit preference signals of users towards items. Given the past preference signals of an individual user, the goal is then to determine the (current) relevance of each recommendable item by combining these individual signals with the preference patterns of the community. The corresponding output of CF algorithms usually is either a set of relevance predictions for each item or a ranked list of items.
1.1.1.Historical Background
Probably the first work that used the term collaborative filtering in today’s meaning in the context of recommender systems was that of Goldberg et al. (1992). In their Tapestry system, users of an experimental corporate email system could define personal filters (using a special query language) for incoming messages that referred to different features of emails, e.g., sender or content. “Collaborative” filters were a special class of filters, which could refer to so-called annotations by other users and one could therefore express that only messages should be retained that were voted positively by other users.
Soon afterwards different proposals were made of how to automate the task of filtering (news) items based on personal preferences and the opinions of other people. Among these proposals was the GroupLens system from Resnick et al. (1994), which proposed the comparably simple heuristic that users who shared similar preferences in the past can be exploited to predict a relevance score (rating) for incoming netnews messages (i.e., a user’s nearest neighbors). While during the past two decades hundreds of different sophisticated algorithms were proposed for the rating prediction task, the problem formalization and the basic heuristic underlying this early work has influenced academic research in the field up to today.
1.1.2.Collaborative Filtering as a Matrix Completion Task
In Resnick et al. (1994), the recommendation problem is considered one of matrix completion (or “matrix filling” as termed in the original work). The input is a matrix where rows and columns represent users and items, respectively, and the cells of the matrix are the known preference statements (ratings) for user-item pairs.
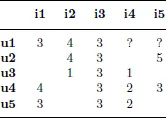
Table 1.1 shows an example matrix where five users (u1 to u5) rated five items (i1 to i5). The recommendable items for user u1 are items i4 and i5 since we assume that the u1 already knows the other items. The question is now if we should recommend H and i5 at all, and if so, in which order the items should be recommended.
Table 1.1.User-item Rating Matrix.
While the ultimate computational task in many applications is to filter and rank the items, many matrix completion approaches solve this indirectly by estimating a relevance score (or, in this case, predicting a rating) for each unknown entry in the cell. While the ranking is determined by these scores, items that do not surpass a minimum threshold need to be filtered.
Over the years, a huge variety of algorithmic approaches has been proposed to accurately predict the missing matrix values, and many of the more advanced ones will be discussed in Chapter 2 of this book. In this chapter, we will mainly focus on early and comparably simple algorithms, including the one proposed by Resnick et al. (1994), which is based on a nearest-neighbor scheme.
Abstracting the recommendation problem to a matrix completion task has different advantages from an academic perspective, as discussed in Jannach and Adomavicius (2016). The computational task is very well defined and the generic nature of the problem formulation allows researchers to design algorithms that are not specific to a certain application domain. Furthermore, different mathematical concepts for data analysis or noise reduction, including principal component analysis or singular value decomposition, can be directly applied on the given data. Finally, over the years, a number of public datasets have become available and agreed-upon evaluation procedures were established in the community (see Section 1.4 in this chapter). These developments, together with the Netflix prize competition2 , geared research efforts on the basis of a matrix completion problem formulation during the last decade. Therefore, most of the chapters in this book will focus on these algorithmic approaches addressing this problem formulation. Nonetheless, as pointed out, e.g., in Jannach et al. (2016b) and Jannach and Adomavicius (2016), there are a number of aspects of practical problems for which matrix completion is not the best problem abstraction. Consequently, we will discuss an alternative problem formulation later in Section 1.1.4.
1.1.3.Basic Algorithms for Matrix Completion
In this section, we will review two basic collaborative filtering algorithms. Both of them are called “memory-based” (in contrast to “model-based” ones) because their recommendations are not based on learning an abstract representation of the data in a pre-processing step. Instead, they load the existing preference signals of the community into memory and implement neighborhood-based strategies to determine suitable recommendations.
1.1.3.1User-based Nearest-Neighbor Algorithms
This algorithm scheme, which is often referred to simply as “user-based CF”, implements the general idea that users “who agreed in the past will probably agree again” (Resnick et al., 1994). To make a relevance prediction under that scheme, i.e., predicting the relevance of item i5 (called “target item”) for user u1 (called the “active user”) in Table 1.1, two main steps have to be done.
(1)Identify a set of N users who exhibit similar rating patterns as u1 (which are often called “neighbors” or “peers”) and for whom a relevance signal for item i5 is known.
(2)Given this set of N similar users and their ratings for item i5, combine their ratings to predict the relevance of i5 for u1.
Consider the following example. When looking at the rating matrix in Table 1.1, we can see that users u2 and u4 have rated item i5, and the question arises if their ratings for i5 would be good predictors for the unknown rating of user u1. The basic assumption is if the ratings of user u1 were highly similar to those of users u2 and u4 then these neighbor’s ratings for i5 should be useful predictors. User u2 rated items i3 and i4 exactly like u1 and user u4 rated them similarly, but did not use identical values.
Now, when implementing the general idea of user-based collaborative filtering in practice, two basic design choices have to be made.
a)How do we assess the similarity of two users?
b)How do we combine the ratings of the similar users?
To answer the first question, Resnick et al. (1994) proposed to use Pearson’s correlation coefficient as a measure to assess if users have similar tastes. Given two users a and b, their similarity is computed as follows, see also Jannach et al. (2011),
where
P is the set of items that were rated both by
a and
b,
ra,p refers to the known rating of user
a for item
p, and the symbol
corresponds to the average rating of user
a. The resulting values range between –1 and +1, where a value +1 indicates that two users have identical tastes and –1 expresses that users have opposite tastes. Values close to 0 are indicators of no or only an insignificant correlation between tastes of two users. One characteristic of the correlation coefficient worth noting is that the measure accounts for different interpretations of the rating scale by two users. Instead of comparing absolute rating values, it compares how a user’s rating for an item deviated from the user’s average rating value.
With respect to the second question of how to combine the relevance predictions given a set of similar users N, Resnick et al. (1994) proposed to use the following function pred(a,p), to predict the rating of user a for item p, see also Jannach et al. (2011).
The idea of this prediction function is to start with the average rating of user a and then consider for each neighbor if item p has been rated above or below the individual average rating. These rating signals of the nearest neighbors are consequently weighted with the similarity between users. Thus the ratings of more similar neighbors have a stronger influence on the derived rating predictions.
Different variations of the scheme proposed by Resnick et al. (1994) are possible along the following dimensions.
•Similarity function: Several standard similarity measures have been explored in the literature including cosine similarity, Spearman’s rho, Jaccard index or Dice coefficient (Herlocker et al., 2004), where the latter measures are only applicable in case the ratings are binary or unary. Furthermore, considering only the user’s deviation from their average rating value for ordinal and continuous rating scales accounts for a consistent under- or over-biasing. In addition, the similarity function could also take the number of co-rated items into account and e.g., apply significance weighting, where the similarity of users with only few co-ratings is reduced (Breese et al., 1998; Herlocker et al., 1999).
•Neighborhood formation: The most common strategies are to select a fixed number of nearest neighbors or to include only those neighbors above a specific similarity threshold. Alternatively, an adaptive neighborhood formation strategy can be implemented that, for instance, could dynamically adjust the similarity threshold to keep the number of nearest neighbors within a predefined range.
•Predict...