
- English
- ePUB (mobile friendly)
- Available on iOS & Android
Introduction to Bayesian Statistics
About this book
"...this edition is useful and effective in teaching Bayesian inference at both elementary and intermediate levels. It is a well-written book on elementary Bayesian inference, and the material is easily accessible. It is both concise and timely, and provides a good collection of overviews and reviews of important tools used in Bayesian statistical methods."
There is a strong upsurge in the use of Bayesian methods in applied statistical analysis, yet most introductory statistics texts only present frequentist methods. Bayesian statistics has many important advantages that students should learn about if they are going into fields where statistics will be used. In this third Edition, four newly-added chapters address topics that reflect the rapid advances in the field of Bayesian statistics. The authors continue to provide a Bayesian treatment of introductory statistical topics, such as scientific data gathering, discrete random variables, robust Bayesian methods, and Bayesian approaches to inference for discrete random variables, binomial proportions, Poisson, and normal means, and simple linear regression. In addition, more advanced topics in the field are presented in four new chapters: Bayesian inference for a normal with unknown mean and variance; Bayesian inference for a Multivariate Normal mean vector; Bayesian inference for the Multiple Linear Regression Model; and Computational Bayesian Statistics including Markov Chain Monte Carlo. The inclusion of these topics will facilitate readers' ability to advance from a minimal understanding of Statistics to the ability to tackle topics in more applied, advanced level books. Minitab macros and R functions are available on the book's related website to assist with chapter exercises. Introduction to Bayesian Statistics, Third Edition also features:
- Topics including the Joint Likelihood function and inference using independent Jeffreys priors and join conjugate prior
- The cutting-edge topic of computational Bayesian Statistics in a new chapter, with a unique focus on Markov Chain Monte Carlo methods
- Exercises throughout the book that have been updated to reflect new applications and the latest software applications
- Detailed appendices that guide readers through the use of R and Minitab software for Bayesian analysis and Monte Carlo simulations, with all related macros available on the book's website
Introduction to Bayesian Statistics, Third Edition is a textbook for upper-undergraduate or first-year graduate level courses on introductory statistics course with a Bayesian emphasis. It can also be used as a reference work for statisticians who require a working knowledge of Bayesian statistics.
Tools to learn more effectively

Saving Books

Keyword Search

Annotating Text

Listen to it instead
Information
CHAPTER 1
INTRODUCTION TO STATISTICAL SCIENCE
Showing a Causal Relationship from Data
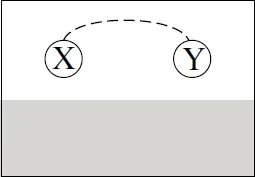
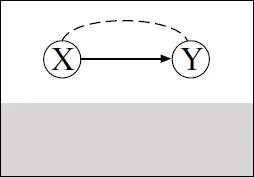
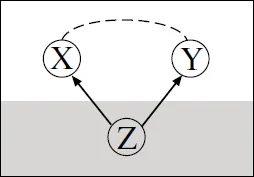
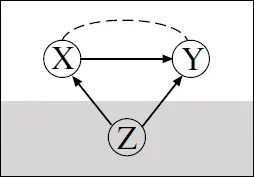
1.1 The Scientific Method: A Process for Learning
- A scientific hypothesis can never be shown to be absolutely true.
- However, it must potentially be disprovable.
- It is a useful model until it is established that it is not true.
- Always go for the simplest hypothesis, unless it can be shown to be false.
- Ask a question or pose a problem in terms of the current scientific hypothesis.
- Gather all the relevant information that is currently available. This includes the current knowledge about parameters of the model.
- Design an investigation or experiment that addresses the question from step 1. The predicted outcome of the experiment should be one thing if the current hypothesis is true, and something else if the hypothesis is false.
- Gather data from the experiment.
- Draw conclusions given the experimental results. Revise the knowledge about the parameters to take the current results into account.
1.2 The Role of Statistics in the Scientific Method
1.3 Main Approaches to Statistics
Table of contents
- Cover
- TitlePage
- Copyright
- Dedication
- Preface
- Chapter 1 Introduction to Statistical Science
- Chapter 2 Scientific Data Gathering
- Chapter 3 Displaying and Summarizing Data
- Chapter 4 Logic, Probability, and Uncertainty
- Chapter 5 Discrete Random Variables
- Chapter 6 Bayesian Inference for Discrete Random Variables
- Chapter 7 Continuous Random Variables
- Chapter 8 Bayesian Inference for Binomial Proportion
- Chapter 9 Comparing Bayesian and Frequentist Inferences for Proportion
- Chapter 10 Bayesian Inference for Poisson
- Chapter 11 Bayesian Inference for Normal Mean
- Chapter 12 Comparing Bayesian and Frequentist Inferences for Mean
- Chapter 13 Bayesian Inference for Difference Between Means
- Chapter 14 Bayesian Inference for Simple Linear Regression
- Chapter 15 Bayesian Inference for Standard Deviation
- Chapter 16 Robust Bayesian Methods
- Chapter 17 Bayesian Inference for Normal with Unknown Mean and Variance
- Chapter 18 Bayesian Inference for Multivariate Normal Mean Vector
- Chapter 19 Bayesian Inference for the Multiple Linear Regression Model
- Chapter 20 Computational Bayesian Statistics Including Markov Chain Monte Carlo
- A Introduction to Calculus
- B Use of Statistical Tables
- C Using the Included Minitab Macros
- D Using the Included R Functions
- E Answers to Selected Exercises
- References
- Index
- EULA
Frequently asked questions
- Essential is ideal for learners and professionals who enjoy exploring a wide range of subjects. Access the Essential Library with 800,000+ trusted titles and best-sellers across business, personal growth, and the humanities. Includes unlimited reading time and Standard Read Aloud voice.
- Complete: Perfect for advanced learners and researchers needing full, unrestricted access. Unlock 1.4M+ books across hundreds of subjects, including academic and specialized titles. The Complete Plan also includes advanced features like Premium Read Aloud and Research Assistant.
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app