
- English
- ePUB (mobile friendly)
- Available on iOS & Android
A Guide to Forensic DNA Profiling
About this book
A Guide to Forensic DNA Profiling
The increasingly arcane world of DNA profiling demands that those requiring to understand at least some of it must find a source of reliable and understandable information. Combining material from the successful Wiley Encyclopedia of Forensic Science with newly commissioned and updated material, the Editors have used their own extensive experience in criminal casework across the world to compile an informative guide that will provide knowledge and thought-provoking articles of interest to anyone involved or interested in the use of DNA in the forensic context.
Following extensive introductory chapters covering forensic DNA profiling and forensic genetics, this comprehensive volume presents a substantial breadth of material covering:
- Fundamental material—including sources of DNA, validation, and accreditation
- Analysis and interpretation—including extraction, quantification, amplification, and interpretation of electropherograms (epgs)
- Evaluation—including mixtures, low template, and transfer
- Applications—databases, paternity and kinship, mitochondrial DNA, wildlife DNA, single-nucleotide polymorphism, phenotyping, and familial searching
- Court—report writing, discovery, cross examination, and current controversies
With contributions from leading experts across the whole gamut of forensic science, this volume is intended to be authoritative but not authoritarian, informative but comprehensible, and comprehensive but concise. It will prove to be a valuable addition, and a useful resource, for scientists, lawyers, teachers, criminologists, and judges.
Tools to learn more effectively

Saving Books

Keyword Search

Annotating Text

Listen to it instead
Information
Part D
Court
Chapter 32
DNA Databases – The Significance of Unique Hits and the Database Controversy
Introduction and the Controversy
- 1. There is a person already identified as a suspect before the DNA profile came up. It so happens that the profile matches with this suspect.
- 2. We run the profile through a database of DNA profiles, and it so happens that there is a unique hit. The person corresponding to this becomes a suspect in the case.
What to recommend in a case in which, after finding exactly one match in a database of size 630.000 […]. The random match probability with 5 analyzed STR loci is in the magnitude of 1 in 600.000. It is in our view inconceivable to assume, in such a situation, that the evidential value due to the database is higher than without a database search. Rather, it seems that the contrary is of significance.
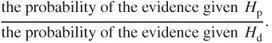
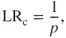
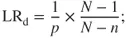
Table of contents
- Cover
- Title Page
- Copyright
- Table of Contents
- Contributors
- Foreword
- Preface
- Glossary
- Abbreviations and Acronyms
- Part A: Background
- Part B: Analysis & Interpretation
- Part C: Applications
- Part D: Court
- Index
- End User License Agreement
Frequently asked questions
- Essential is ideal for learners and professionals who enjoy exploring a wide range of subjects. Access the Essential Library with 800,000+ trusted titles and best-sellers across business, personal growth, and the humanities. Includes unlimited reading time and Standard Read Aloud voice.
- Complete: Perfect for advanced learners and researchers needing full, unrestricted access. Unlock 1.4M+ books across hundreds of subjects, including academic and specialized titles. The Complete Plan also includes advanced features like Premium Read Aloud and Research Assistant.
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app