Hands-On Reinforcement Learning with Python
Master reinforcement and deep reinforcement learning using OpenAI Gym and TensorFlow
Sudharsan Ravichandiran
- 318 pages
- English
- ePUB (adapté aux mobiles)
- Disponible sur iOS et Android
Hands-On Reinforcement Learning with Python
Master reinforcement and deep reinforcement learning using OpenAI Gym and TensorFlow
Sudharsan Ravichandiran
À propos de ce livre
A hands-on guide enriched with examples to master deep reinforcement learning algorithms with Python
Key Features
- Your entry point into the world of artificial intelligence using the power of Python
- An example-rich guide to master various RL and DRL algorithms
- Explore various state-of-the-art architectures along with math
Book Description
Reinforcement Learning (RL) is the trending and most promising branch of artificial intelligence. Hands-On Reinforcement learning with Python will help you master not only the basic reinforcement learning algorithms but also the advanced deep reinforcement learning algorithms.
The book starts with an introduction to Reinforcement Learning followed by OpenAI Gym, and TensorFlow. You will then explore various RL algorithms and concepts, such as Markov Decision Process, Monte Carlo methods, and dynamic programming, including value and policy iteration. This example-rich guide will introduce you to deep reinforcement learning algorithms, such as Dueling DQN, DRQN, A3C, PPO, and TRPO. You will also learn about imagination-augmented agents, learning from human preference, DQfD, HER, and many more of the recent advancements in reinforcement learning.
By the end of the book, you will have all the knowledge and experience needed to implement reinforcement learning and deep reinforcement learning in your projects, and you will be all set to enter the world of artificial intelligence.
What you will learn
- Understand the basics of reinforcement learning methods, algorithms, and elements
- Train an agent to walk using OpenAI Gym and Tensorflow
- Understand the Markov Decision Process, Bellman's optimality, and TD learning
- Solve multi-armed-bandit problems using various algorithms
- Master deep learning algorithms, such as RNN, LSTM, and CNN with applications
- Build intelligent agents using the DRQN algorithm to play the Doom game
- Teach agents to play the Lunar Lander game using DDPG
- Train an agent to win a car racing game using dueling DQN
Who this book is for
If you're a machine learning developer or deep learning enthusiast interested in artificial intelligence and want to learn about reinforcement learning from scratch, this book is for you. Some knowledge of linear algebra, calculus, and the Python programming language will help you understand the concepts covered in this book.
Foire aux questions
Informations
Deep Learning Fundamentals
- Artificial neurons
- Artificial neural networks (ANNs)
- Building a neural network to classify handwritten digits
- RNNs
- LSTMs
- Generating song lyrics using LSTMs
- CNNs
- Classifying fashion products using CNNs
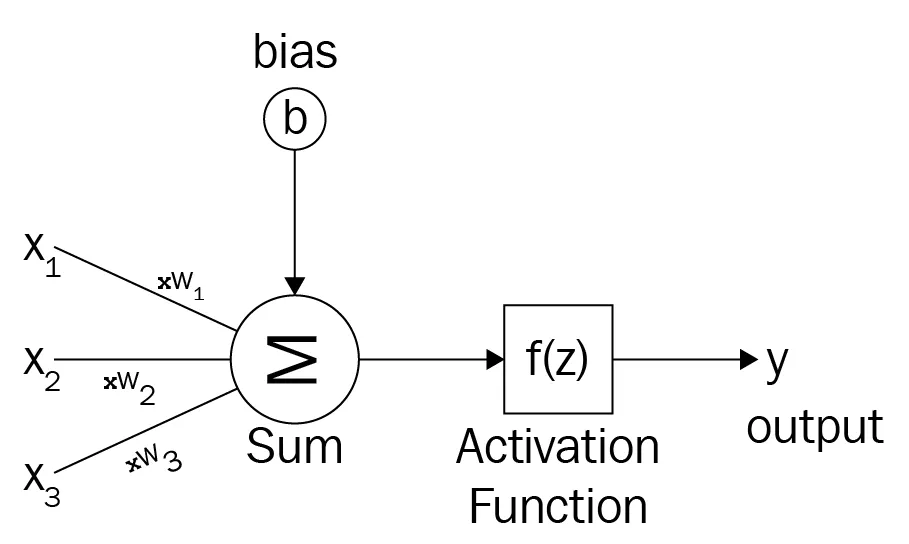
Artificial neurons


ANNs
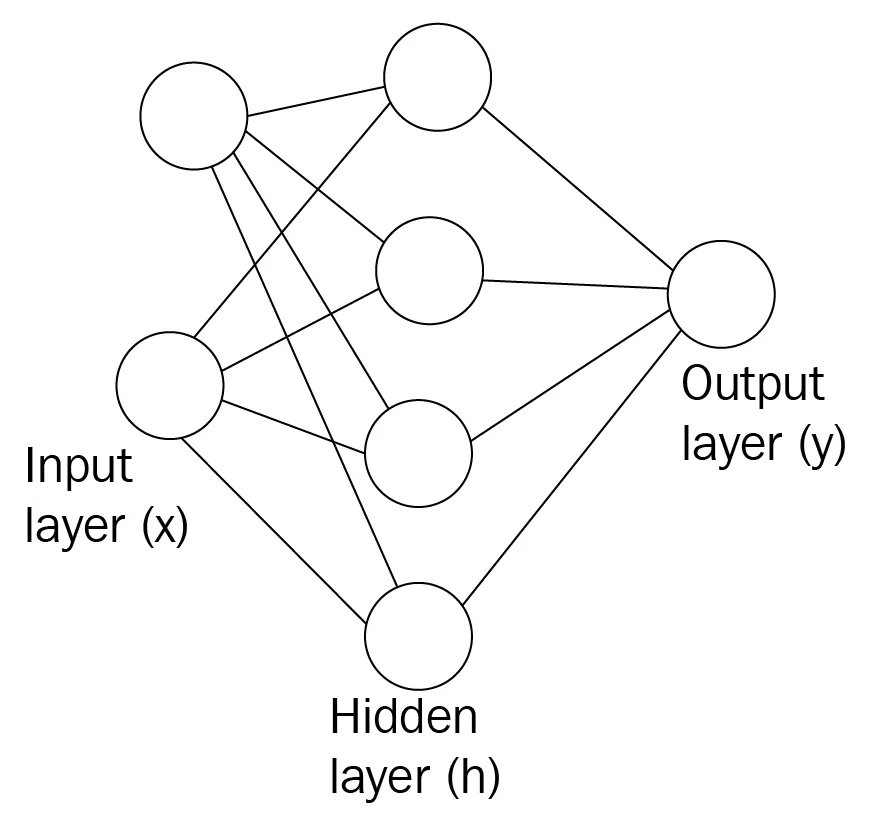
- Input layer
- Hidden layer
- Output layer