Computer Science
Harvard Architecture
Harvard Architecture is a computer architecture that separates memory and processing units. It uses separate buses for instructions and data, allowing for simultaneous access to both. This architecture is commonly used in embedded systems and digital signal processing applications.
Written by Perlego with AI-assistance
Related key terms
1 of 5
6 Key excerpts on "Harvard Architecture"
 eBook - ePub
eBook - ePubModern Computer Architecture and Organization
Learn x86, ARM, and RISC-V architectures and the design of smartphones, PCs, and cloud servers
- Jim Ledin(Author)
- 2020(Publication Date)
- Packt Publishing(Publisher)
The Harvard Architecture potentially provides a higher performance level by parallelizing accesses to instructions and data. This architecture also removes the entire class of security issues associated with maliciously executing data as program instructions, as long as the instruction memory cannot be modified by program instructions. This assumes that the program memory is loaded with instructions in a trustworthy manner.In hindsight, with knowledge of the proliferation of von Neumann architecture-enabled security threats, there is reason to wonder whether the entire information technology industry would not have been vastly better off had there been early agreement to embrace the Harvard Architecture and its complete separation of code and data memory regions, despite the costs involved.In practice, a strict Harvard Architecture is rarely used in modern computers. Several variants of the Harvard Architecture are commonly employed, under the name modified Harvard Architecture.The modified Harvard Architecture
Computers designed with a modified Harvard Architecture have, in general, some degree of separation between program instructions and data. This separation is rarely absolute. While systems with modified Harvard Architectures contain separate program instruction and data memory regions, such systems typically support some means of storing data in program memory and, in some cases, storing instructions in data memory.The following diagram shows a typical modified Harvard Architecture representing a variety of real-world computer systems:Figure 7.3: Modified Harvard ArchitectureAs we saw in the previous chapter, digital signal processors (DSPs) achieve substantial benefits from the use of a Harvard-like architecture. By storing one numeric vector in instruction memory and a second vector in data memory, a DSP can execute one multiply-accumulate (MAC) operation per processor clock cycle. In these systems, instruction memory and the data elements it contains are typically read-only memory devices. This is indicated by the unidirectional arrow connecting the instruction memory to the processor in Figure 7.3. Consequently, only constant data values are suitable for storage in the instruction memory region. eBook - PDF
eBook - PDF- Alvin Albuero De Luna(Author)
- 2023(Publication Date)
- Arcler Press(Publisher)
Figure 2.3. Harvard Architecture. Source: https://www.w3schools.in/computer-fundamentals/types-of-computer- architecture. The enhanced Harvard Architecture machine is similar to a Harvard Architecture machine in that the independent instructions and data caches share the same address space. It features digital signal processors (DSPs) that can run simple or complex audio or video algorithms, and can be replicated (Konyavsky and Ross, 2019). Microcontrollers have a limited amount of programs and information memory, and they speed up processing via running concurrent commands and accessing information. In Figure 2.4, we may see that there are separate instructions and data memory, as well as a bus for performing operations. It’s contained within the CPU. It contains a distinct arithmetic and logic unit and may execute simultaneous I/O operations (Kong et al., 2010). Classification of Computer Architecture 55 Data and instructions have been both kept in a similar memory in a normal computer which obeys the architecture of von Neumann. Data and instructions are transported on the same buses. This indicates the CPU can’t perform both (the write/read data and read the instruction) at a similar time. The Harvard Architecture is a type of computer architecture that features separate command and storage of data, as well as separate bus systems (signal paths). It was developed to circumvent the bottleneck of Von Neumann Architecture. Having separate command and information buses provides the essential advantage of allowing the CPU to retrieve instructions while also reading and writing data at the same time (Li and Yan, 2010). The Harvard Architecture structure is explained in the following subsections. 2.3.1. Buses Buses are used as traffic signal vehicles. In Harvard’s architecture, the data and instruction buses are segregated from one another. Buses are available in a range of designs and capacities (Chung, 1995; Ben Mahjoub and Atri, 2019). eBook - ePub
eBook - ePub- Jim Ledin, Dave Farley(Authors)
- 2022(Publication Date)
- Packt Publishing(Publisher)
The Harvard Architecture potentially provides a higher performance level by parallelizing accesses to instructions and data. This architecture also removes the entire class of security issues associated with maliciously executing data as program instructions, provided the instruction memory cannot be modified by program instructions. This assumes the program memory is loaded with instructions in a trustworthy manner.In hindsight, with knowledge of the proliferation of von Neumann architecture-enabled security threats, there is reason to wonder if the entire information technology industry would not have been vastly better off had there been early agreement to embrace the Harvard Architecture and its complete separation of code and data memory regions, despite the costs involved.In practice, a strict Harvard Architecture is rarely used in modern computers. Several variants of the Harvard Architecture are commonly employed, collectively called modified Harvard Architectures . These architectures are the topic of the next section.The modified Harvard Architecture
Computers designed with a modified Harvard Architecture have, in general, some degree of separation between program instructions and data. This reduces the effects of the von Neumann bottleneck and mitigates the security issues we’ve discussed. The separation between instructions and data is rarely absolute, however. While systems with modified Harvard Architectures contain separate program instruction and data memory regions, these processors typically support some means of storing data in program memory and, in some cases, storing instructions in data memory.The following diagram shows a modified Harvard Architecture representing many real-world computer systems: Figure 7.3: Modified Harvard ArchitectureAs we saw in the previous chapter, digital signal processors (DSPs ) achieve substantial benefits from the use of a Harvard-like architecture.By storing one numeric vector in instruction memory and a second vector in data memory, a DSP can execute one multiply-accumulate (MAC ) operation per processor clock cycle. In these systems, instruction memory and the data elements it contains are typically read-only memory regions. This is indicated by the unidirectional arrow connecting the instruction memory to the processor in Figure 7.3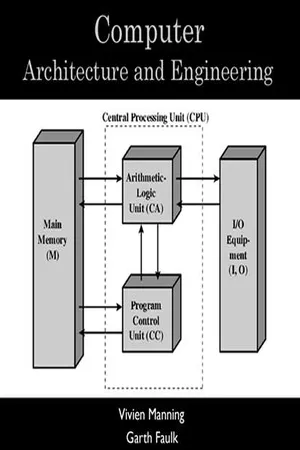 No longer available |Learn more
No longer available |Learn more- (Author)
- 2014(Publication Date)
- College Publishing House(Publisher)
A Harvard Architecture computer can thus be faster for a given circuit complexity because instruction fetches and data access do not contend for a single memory pathway . Also, a Harvard Architecture machine has distinct code and data address spaces: inst-ruction address zero is not the same as data address zero. Instruction address zero might identify a twenty-four bit value, while data address zero might indicate an eight bit byte that isn't part of that twenty-four bit value. Contrast with Modified Harvard Architecture A modified Harvard Architecture machine is very much like a Harvard Architecture machine, but it relaxes the strict separation between instruction and data while still letting the CPU concurrently access two (or more) memory buses. The most common modi-fication includes separate instruction and data caches backed by a common address space. While the CPU executes from cache, it acts as a pure Harvard machine. When accessing backing memory, it acts like a von Neumann machine (where code can be moved around like data, a powerful technique). This modification is widespread in modern processors such as the ARM architecture and X86 processors. It is sometimes loosely called a Harvard Architecture, overlooking the fact that it is actually modified. Another modification provides a pathway between the instruction memory (such as ROM or flash) and the CPU to allow words from the instruction memory to be treated as read-only data. This technique is used in some microcontrollers, including the Atmel AVR. This allows constant data, such as text strings or function tables, to be accessed without first having to be copied into data memory, preserving scarce (and power-hungry) data memory for read/write variables. Special machine language instructions are provided to read data from the instruction memory. No longer available |Learn more
No longer available |Learn more- (Author)
- 2014(Publication Date)
- Learning Press(Publisher)
A Harvard Architecture computer can thus be faster for a given circuit complexity because instruction fetches and data access do not contend for a single memory pathway . Also, a Harvard Architecture machine has distinct code and data address spaces: instru-ction address zero is not the same as data address zero. Instruction address zero might identify a twenty-four bit value, while data address zero might indicate an eight bit byte that isn't part of that twenty-four bit value. Contrast with Modified Harvard Architecture A modified Harvard Architecture machine is very much like a Harvard Architecture machine, but it relaxes the strict separation between instruction and data while still letting the CPU concurrently access two (or more) memory buses. The most common modi-fication includes separate instruction and data caches backed by a common address space. While the CPU executes from cache, it acts as a pure Harvard machine. When accessing backing memory, it acts like a von Neumann machine (where code can be moved around like data, a powerful technique). This modification is widespread in modern processors such as the ARM architecture and X86 processors. It is sometimes loosely called a Harvard Architecture, overlooking the fact that it is actually modified. Another modification provides a pathway between the instruction memory (such as ROM or flash) and the CPU to allow words from the instruction memory to be treated as read-only data. This technique is used in some microcontrollers, including the Atmel AVR. This allows constant data, such as text strings or function tables, to be accessed without first having to be copied into data memory, preserving scarce (and power-hungry) data memory for read/write variables. Special machine language instructions are provided to read data from the instruction memory.
- Hesham El-Rewini, Mostafa Abd-El-Barr(Authors)
- 2005(Publication Date)
- Wiley-Interscience(Publisher)
Based on the interface between different levels of the system, a number of computer architectures can be defined. The interface between the application programs and a high-level language is referred to as a language architecture. The instruction set architecture defines the interface between the basic machine instruction set and the runtime and I/O control. A different definition of computer architecture is built on four basic viewpoints. These are the structure, the organization, the implementation, and the performance. In this definition, the structure defines the interconnection of various hardware com- ponents, the organization defines the dynamic interplay and management of the various components, the implementation defines the detailed design of hardware components, and the performance specifies the behavior of the computer system. Architectural development and styles are covered in Section 1.2. 1 Fundamentals of Computer Organization and Architecture, by M. Abd-El-Barr and H. El-Rewini ISBN 0-471-46741-3 Copyright # 2005 John Wiley & Sons, Inc. A number of technological developments are presented in Section 1.3. Our discus- sion in this chapter concludes with a detailed coverage of CPU performance measures. 1.1. HISTORICAL BACKGROUND In this section, we would like to provide a historical background on the evolution of cornerstone ideas in the computing industry. We should emphasize at the outset that the effort to build computers has not originated at one single place. There is every reason for us to believe that attempts to build the first computer existed in different geographically distributed places. We also firmly believe that building a computer requires teamwork. Therefore, when some people attribute a machine to the name of a single researcher, what they actually mean is that such researcher may have led the team who introduced the machine.
Index pages curate the most relevant extracts from our library of academic textbooks. They’ve been created using an in-house natural language model (NLM), each adding context and meaning to key research topics.